Prompt工程如此强大,我们还需要模型训练吗?
今天偶然间看到了斯坦福大学CS224N——深度学习自然语言处理(NLP with DL)——的prompting和RLHF这一讲的课件,读完之后顿觉醍醐灌顶,再加上课件本身逻辑清晰、内容层层推进且覆盖了NLP领域最新进展(2023年冬季课程),于是对此课件进行简要总结,以备后续不时之需。
今天就先总结下最近最火的ChatGPT背后的技术及相关技术的演变过程。
官方课件链接如下:
https://web.stanford.edu/class/cs224n/slides/cs224n-2023-lecture11-prompting-rlhf.pdf这一讲的标题是prompting(提示词)和RLHF(Reinforcement Learning from Human Feedback,人类反馈的强化学习),主题是从语言模型到人工智能助手,乍一看就能猜到这一讲大致就是讲如何利用prompting和RLHF技术使得NLP从语言模型进化到人工智能助手的。具体分为了下面三节:
- Zero-Shot (ZS) and Few-Shot (FS) In-Context Learning——基于上下文的零样本学习和少样本学习
- Instruction finetuning——指令微调
- Reinforcement Learning from Human Feedback (RLHF)——人类反馈的强化学习
下面就简要介绍一下这三节主要讲了什么(方便与原始课件对齐,下面的标题均采用英文原始表述)。
Zero-Shot (ZS) and Few-Shot (FS) In-Context Learning
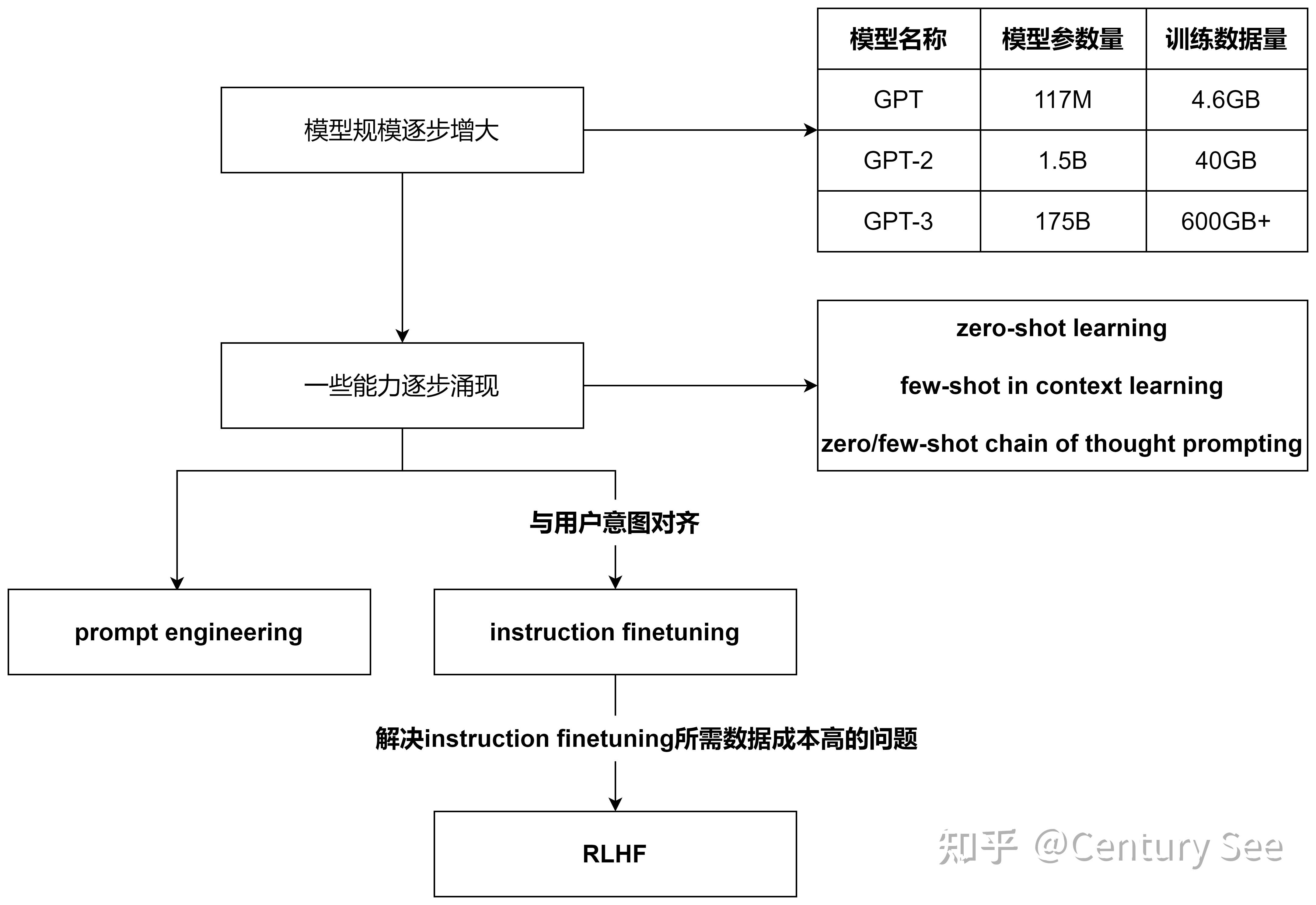
这一节先从GPT模型的演进引入,首先表述了随着模型参数和训练数据的增大,语言模型逐步涌现(emerging)出了一些能力,这些从GPT对应的论文就可以看出端倪。
GPT-2对应的论文 Language Models are Unsupervised Multitask Learners ,讲述了语言模型是无监督的多任务学习器,在论文中,进一步阐述了预训练好的GTP-2模型在没有进行微调和参数更新的的情况下,在8个零样本学习的任务中取得了7个任务的SOTA。这表明此时的GPT-2已经涌现出了零样本学习的能力。
GPT-3的论文 Language Models are Few-Shot Learners,讲述了语言模型是少样本学习器。在这篇论文里,作者们阐述了在简单的任务前添加少量样例的情况下(Specify a task by simply prepending examples of the task before your example),语言模型也能够SOTA的结果。这说明GPT-3已经涌现出了基于上下文的少样本学习能力。同时,添加到任务前的样例也可以看作是一种prompting。
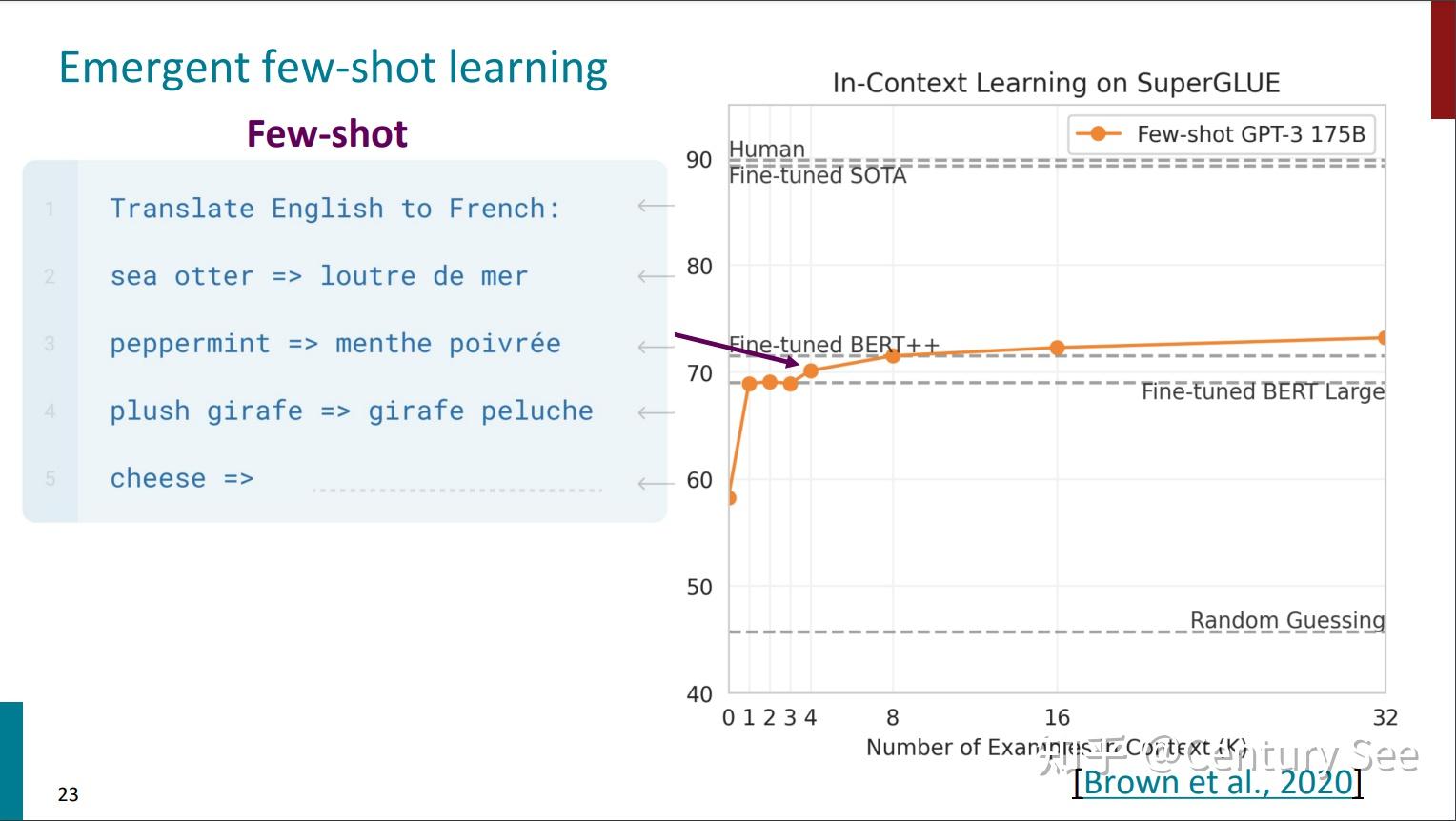
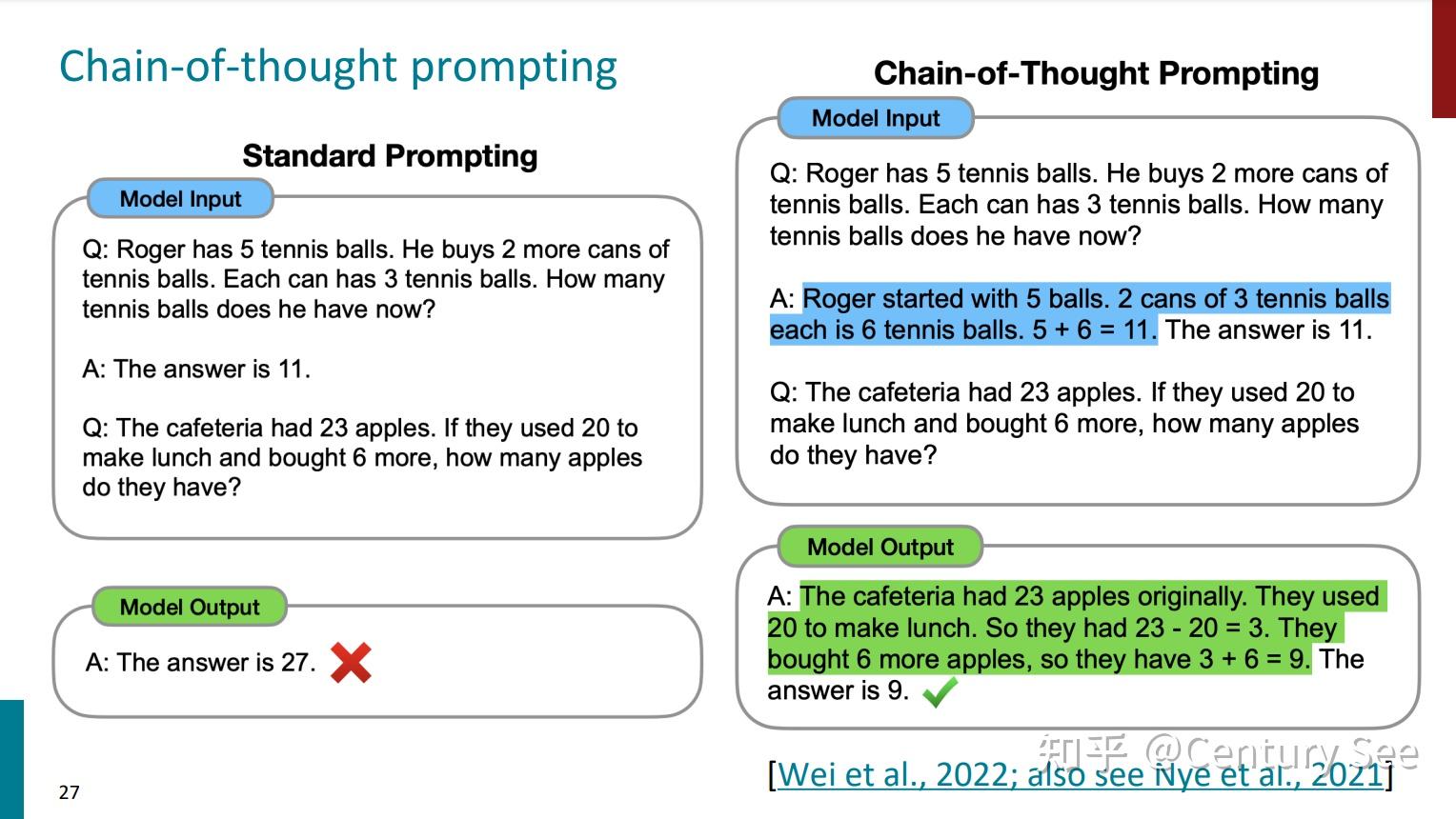
但是,对于复杂的任务(数学运算、逻辑推理等等),简单的给出结果并不能使模型给出正确的结果。此时,需要将提示词更换一种形式,这就引出了思维链提示词(Chain of Thought prompting,以下简称CoT Prompting)。简单地说,就是将推导的过程添加到提示词中。如下图所示:
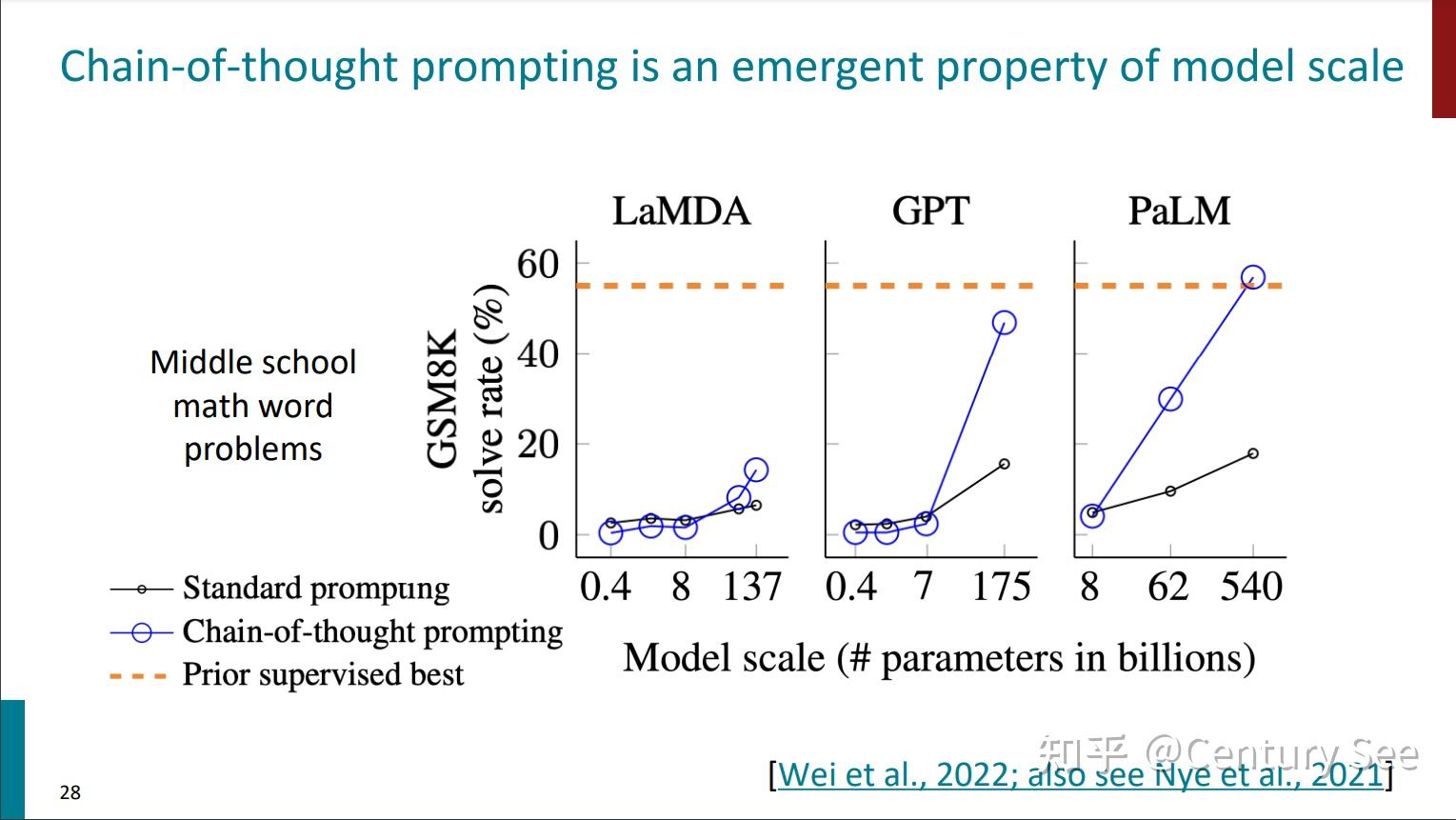
同时,Chain of Thought Prompting这个能力也是随着模型尺度的增大而出现的。
同时,也有工作探索了Zero-shot CoT Prompting和few-shot CoT Prompting,进而发现了一片新大陆——prompting engineering。
Instruction Finetuning
之所以有这个工作,是因为大模型生成的结果,与人类的偏好还是有些偏差,或者说没有跟用户的意图对齐(not aligned with user intent)。为了保持模型现有的zero-shot、few-shot、CoT能力,自然而然地想到可以在预训练好的大模型上进行微调(finetuing),只不过这时的微调与之前的微调有所区别——即这时的微调是多任务的微调。具体而言,就是将不同的任务抽象为(instruction, output)二元组,喂给模型,同时更新模型参数。
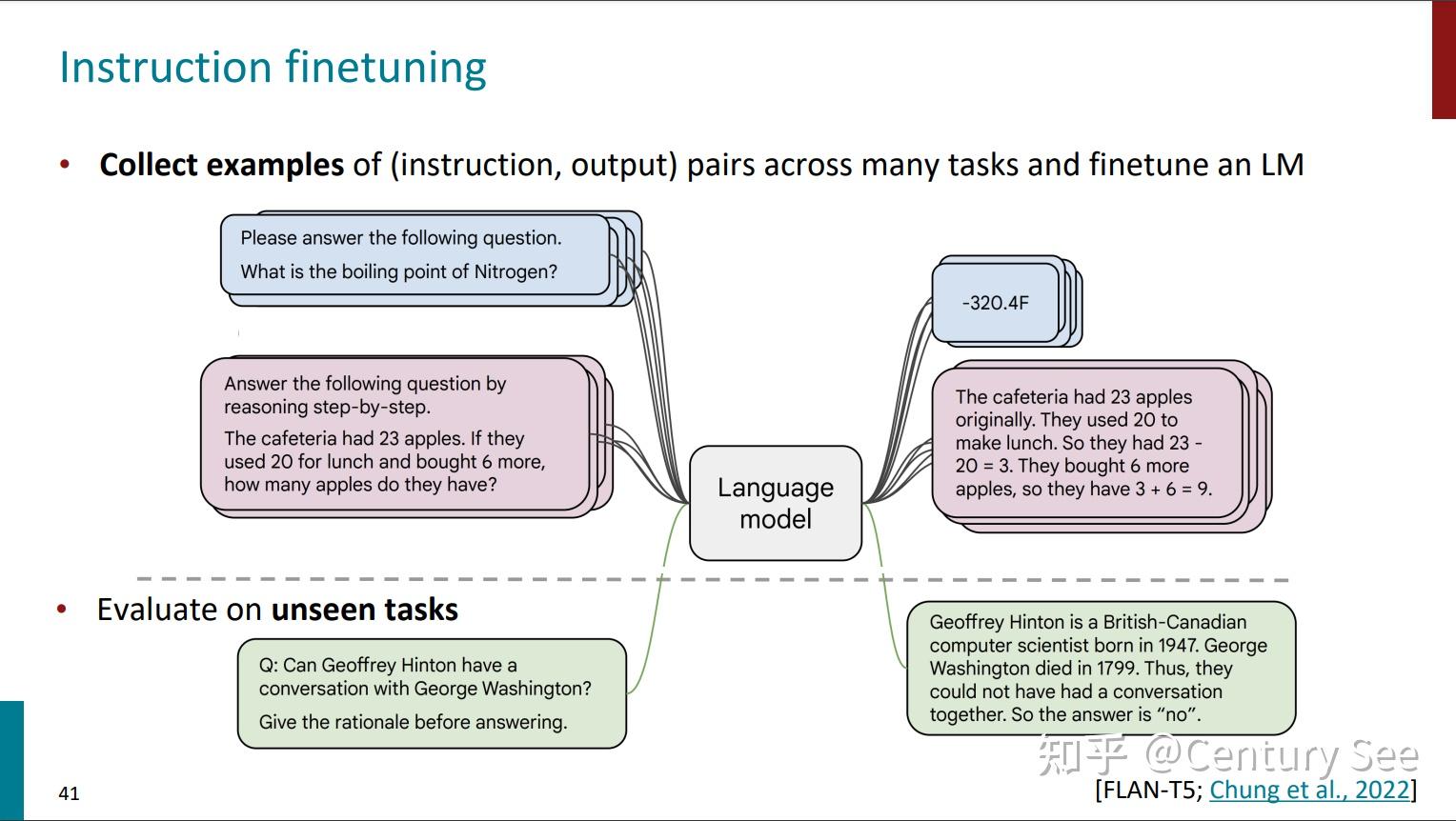
需要注意的是,这一步就有点像预训练了,需要很大的数据集和很大的模型。所以课件中戏称instruction finetuning为instruction pretraining,成了两阶段预训练。目前,也已经有了对应的数据集:
- SuperNaturalInstructions dataset(1,600+任务,3,000,000+样例)
- BIG-bench
显然,instruction finetuing的缺点有两个:
- 数据准备代价巨大
- 语言模型对错误token的惩罚使用同样的权重,这一点与人类偏好不一样
为了解决上述两个缺点,RLHF出场了
Reinforcement Learning from Human Feedback (RLHF)
因为涉及到较的公式,这一部分的原理就不再详细解释了,说一下简单的思路。
为了解决instruction finetuning中存在的数据准备代价大的问题,一个直观的想法就是是否可以用模型生成的内容作为人工构造内容的平替。为了达到这个目的,一种做法就是利用强化学习。强化学习基本知识可以参考王树森和张志华老师写的一本书——《深度强化学习》,这本书还有对应的视频教程,讲解深入浅出,值得一看。
为了应用强化学习,需要构造出一个reward函数,该函数将语言模型生成的句子作为输入,输出句子对应的评分。如何构造出reward函数呢,这里采用了一个神经网络来对奖励进行学习,但是如果直接对句子进行评分的话,人的主观因素对结果影响过大,这里采用两个句子的相对得分对模型进行训练。
有了reward函数,以及初始的语言模型,再有一个依据reward对语言模型参数进行更新的策略,就可以进行RLHF了。具体如下图所示:
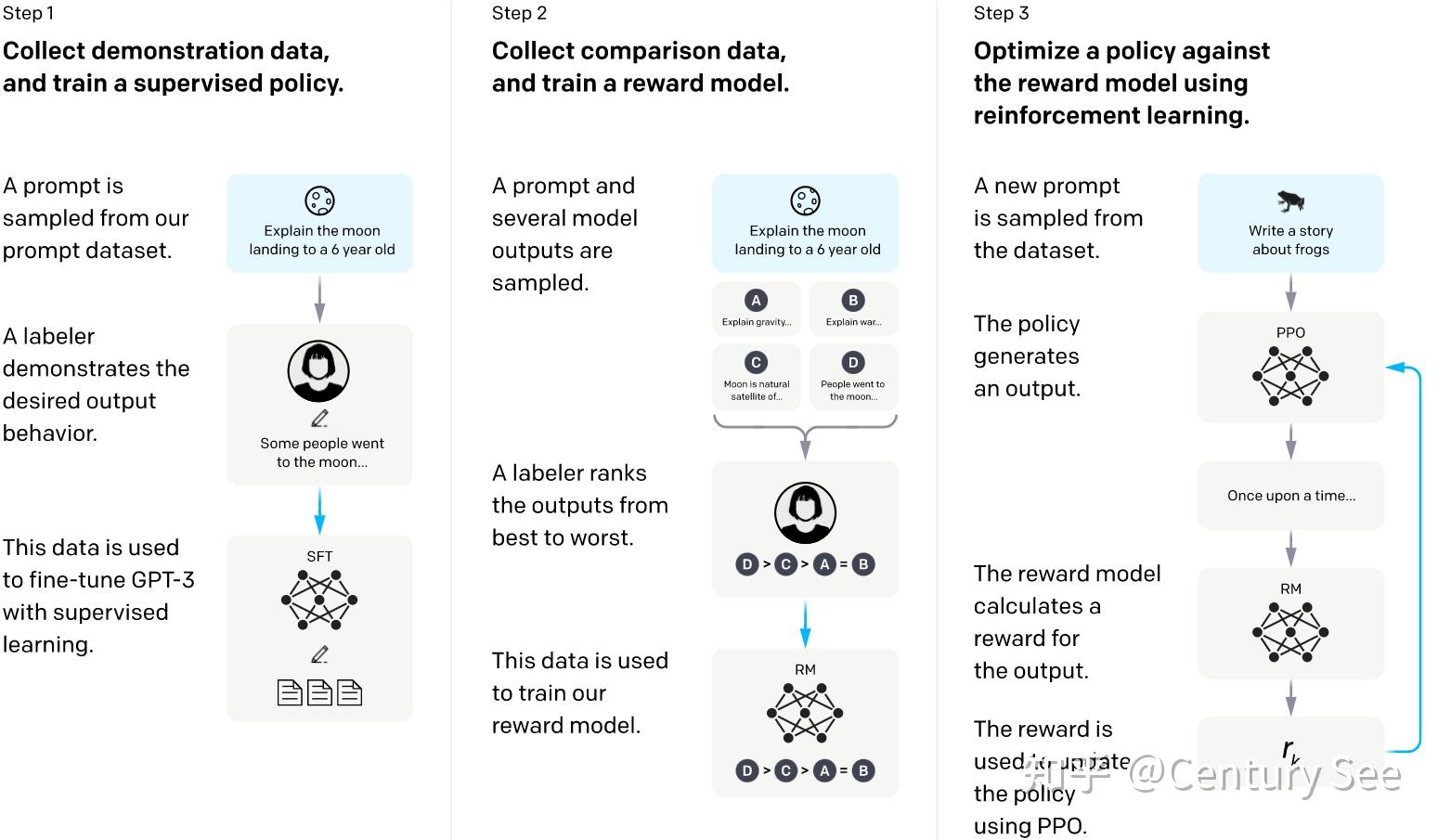
同时,有篇论文对仅预训练、Instruction Finetuning、RLHF的效果进行了对比,结果如下:
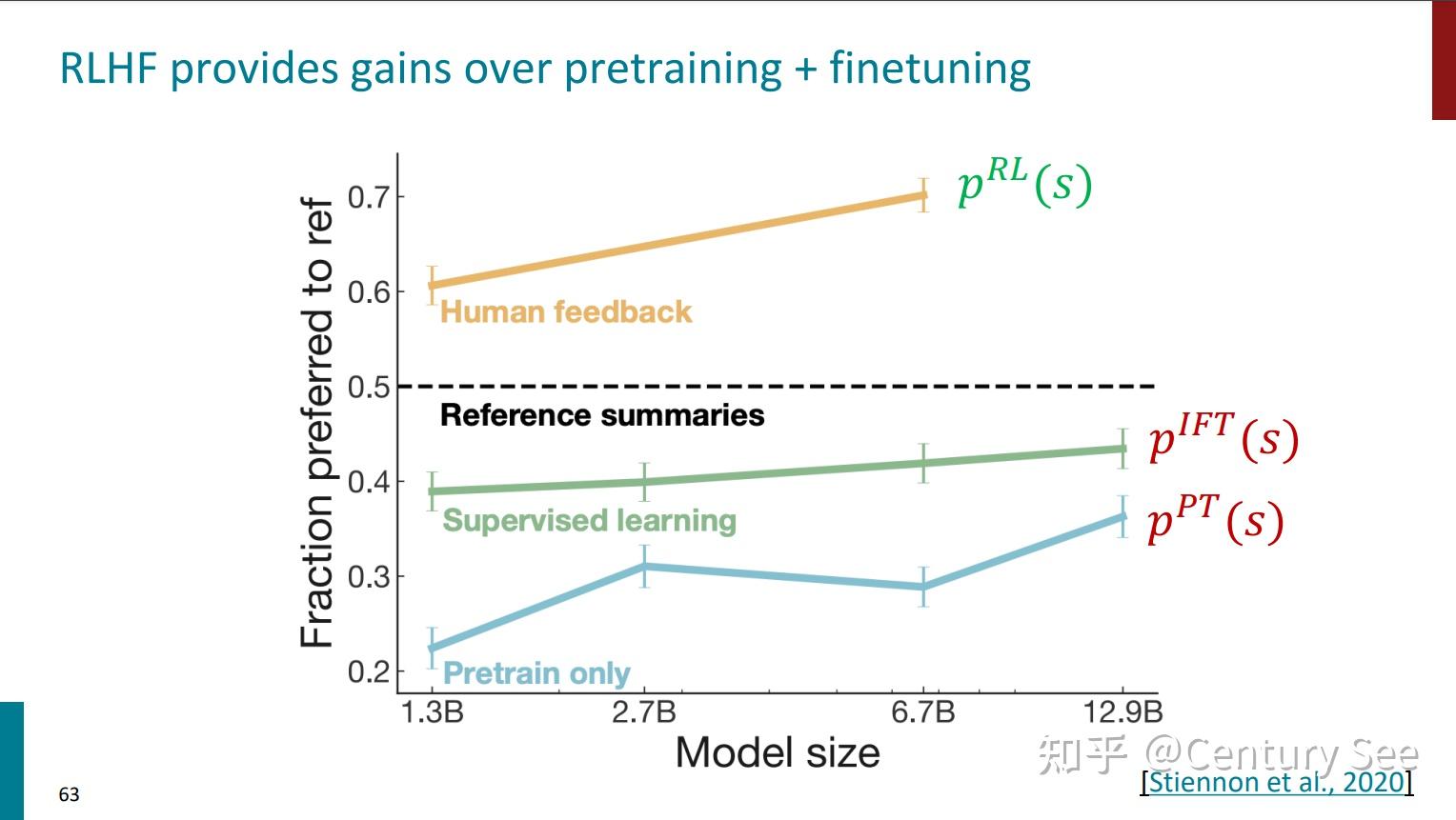
但是,最后还要说明一点,采用了RLHF方法的模型,虽然能够产生看上去更权威更有帮助的结果,但生成结果的真实性却值得商榷。(Chatbots are rewarded to produce responses that seem authoritative and helpful, regardless of truth)
这一节的内容就到这里,最后做个总结:
更多相关内容与相关课件论文下载,欢迎关注【算法工程笔记】微信公众号。