 "模型"搜索结果 9 条
"模型"搜索结果 9 条
在将来的大模型发展中,大模型生成数据是否是解决高质量数据不足的方法,如果不是有什么方法解决数据不足?
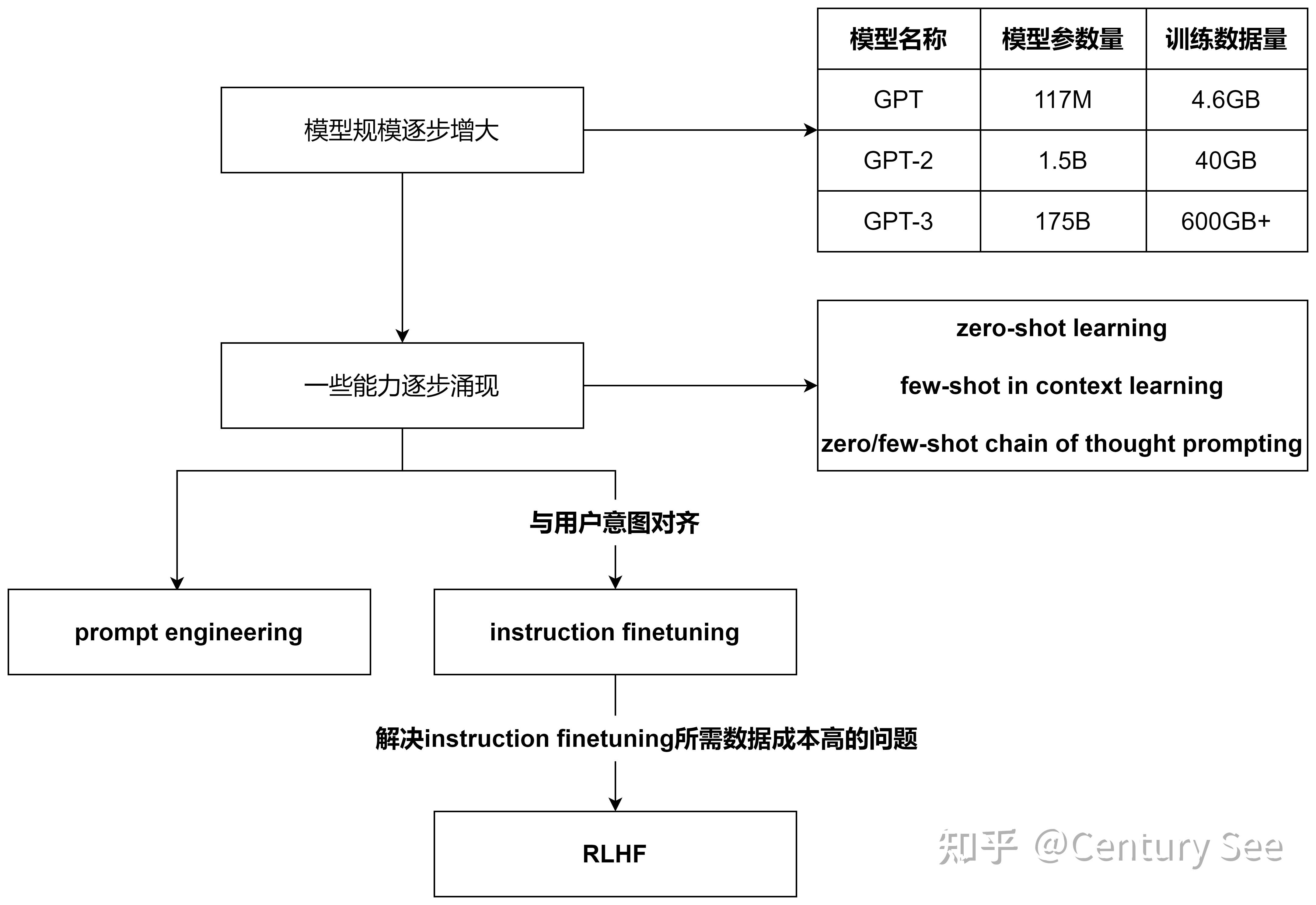
当前的大模型通常指的是拥有数十亿甚至更多参数的预训练神经网络模型,在这个定义中有两个重要的关键点,一个是“数十亿以上的参数规模”,另一个是“预训练神经网络”。数十亿以上的参数规模意味着巨大的参数规模和夸张的算力要求,同时“预训练的神经网络”意味着需要庞大的数据和算力进行训练。所以这个定义很好的反映了大模型缩放定律的三个要素——算力、数据规模、参数规模。这三要素说明了,要训练好一个大模型,足够优质…
Prompt工程如此强大,我们还需要模型训练吗?
今天偶然间看到了斯坦福大学CS224N——深度学习自然语言处理(NLP with DL)——的prompting和RLHF这一讲的课件,读完之后顿觉醍醐灌顶,再加上课件本身逻辑清晰、内容层层推进且覆盖了NLP领域最新进展(2023年冬季课程),于是对此课件进行简要总结,以备后续不时之需。 今天就先总结下最近最火的ChatGPT背后的技术及相关技术的演变过程。 官方课件链接如下: https://web.stanford.edu/class/cs224n/slides/cs224n-2023-lecture11-prompting-rlhf.pdf 这一讲的标题是 prompting(提示词)和RLHF(R…
actor模型中的消息通知机制是怎样的?
C++中的Actor模型是一种并发编程模型,它通过将计算单元封装为独立、可并发执行的Actor实例,来实现并发和消息传递。每个Actor都有自己的状态和行为,并且通过接收和发送消息来进行通信。Actor之间是完全隔离的,它们之间只能通过消息进行通信,从而避免了共享状态和显式锁的问题。 下面是一个简单的C++ Actor模型的示例实现: #include
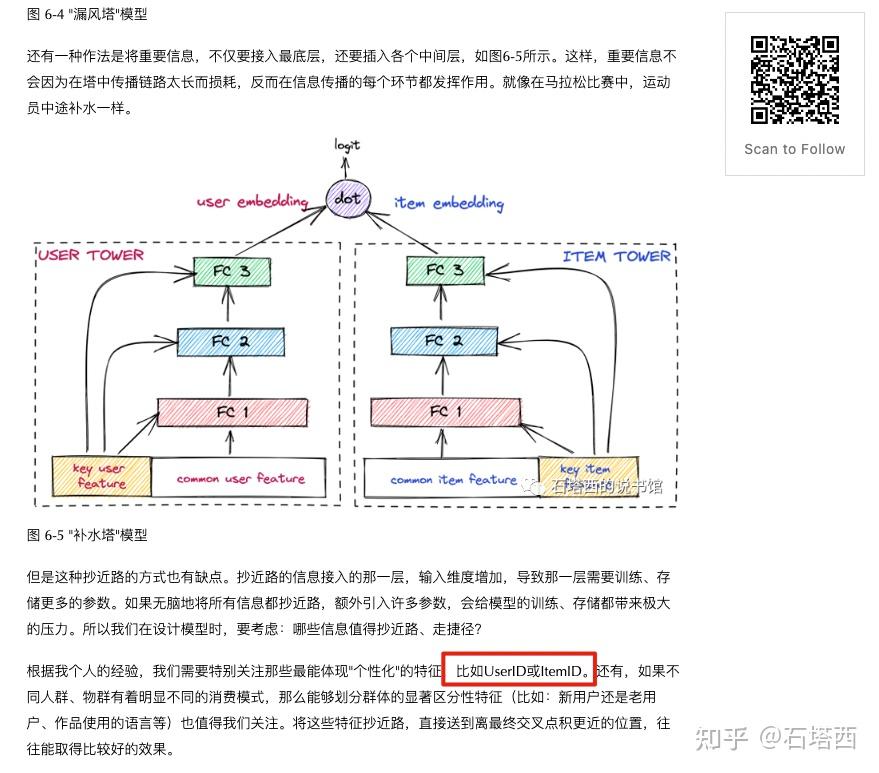
深度学习推荐算法中user-id和item-id是否需要放入模型中作为特征进行训练呢?
大厂会将user id / item id作为特征加入推荐模型,因为他们的数据足够多,算力足够强。 大厂的APP的资深用户的行为足够将他们的user id embedding训练出来。 大厂APP的热门物料会曝光十几万、甚至几十万次,这么多日志足够将这些item id embedding充分训练出来。 如果小厂的推荐模型就不建议使用这些id当embedding了,数据不够,你加进去也学习不出来。 在《 互联网大厂推荐算法实战 》对这一问题有专门的论述。互联网大厂推荐算…
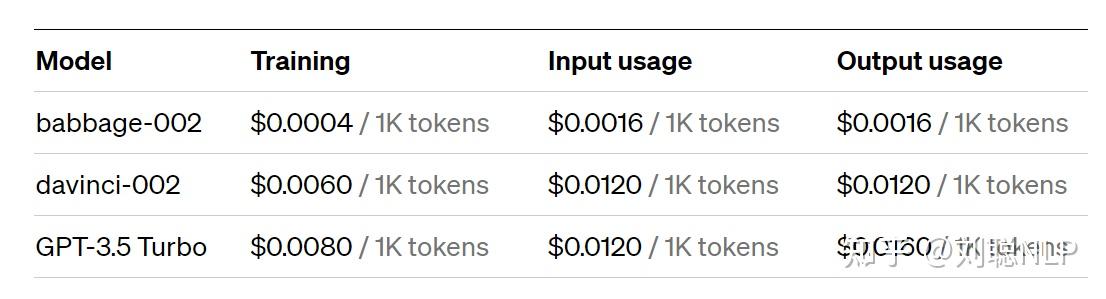
OpenAI 开放 GPT-3.5 Turbo 微调接口,企业还有必要自研大模型吗?
先说结论:企业自研大模型是必要的。早上看到GPT-3.5-Turbo支持微调时,心里咯噔一下,心想:“ OpenAI不当人,下来抢我蛋糕了”。群里也是一帮人在讨论这个事情。但经过深思熟虑之后,并不影响我们继续企业自研,虽然支持微调,但并没解决最核心的问题: “数据外泄”。 因此,企业自研大模型是必要的。当然数据外泄包含两种:“数据出境”和“数据出企业”,很多企业因为国家规定,核心机密数据是不可以出境的,因此无法使用, …
最近大模型遍地开花,你在大模型实践过程中的经验有哪些?
经验谈不上,教训有很多,先想到这么几个: 用成熟的分布式训练框架:多用 DeepSpeed,少用 Pytorch 原生的 torchrun。在节点数量较少的情况下,使用哪种训练框架并不是特别重要;然而,一旦涉及到数百个节点,DeepSpeed的优点就显得很明显,其简便的启动和便于性能分析的特点使其成为理想之选。 弹性容错和自动重启机制:大模型训练不是以往那种单机训个几小时就结束的任务,往往需要训练好几周甚至好几个月,这时候你就知道能…
很多老师都用1.01的365次方和0.99的365次方论证要坚持每天进步,可这个模型跟实际相符吗?
这是一个好问题。 它好就好在,演示了大好青年们是怎么被贷款一步一步忽悠进去的 原因在于:很多人对指数增长的复利没有概念,以为日息 1.01 是一个很小的数字,其实并不是。每日 1.01 是个极为恐怖的数字。每日 1.0001 才是比较正常合理的数值。 20%的年利率,被称为高利贷,困在高利贷中的用户,我们有篇古文背过: 一年借,十年还,几辈子,还不完。注意,这篇文章并没有使用夸张的修辞手法。因为 20% 的利率借十年是真的还不…
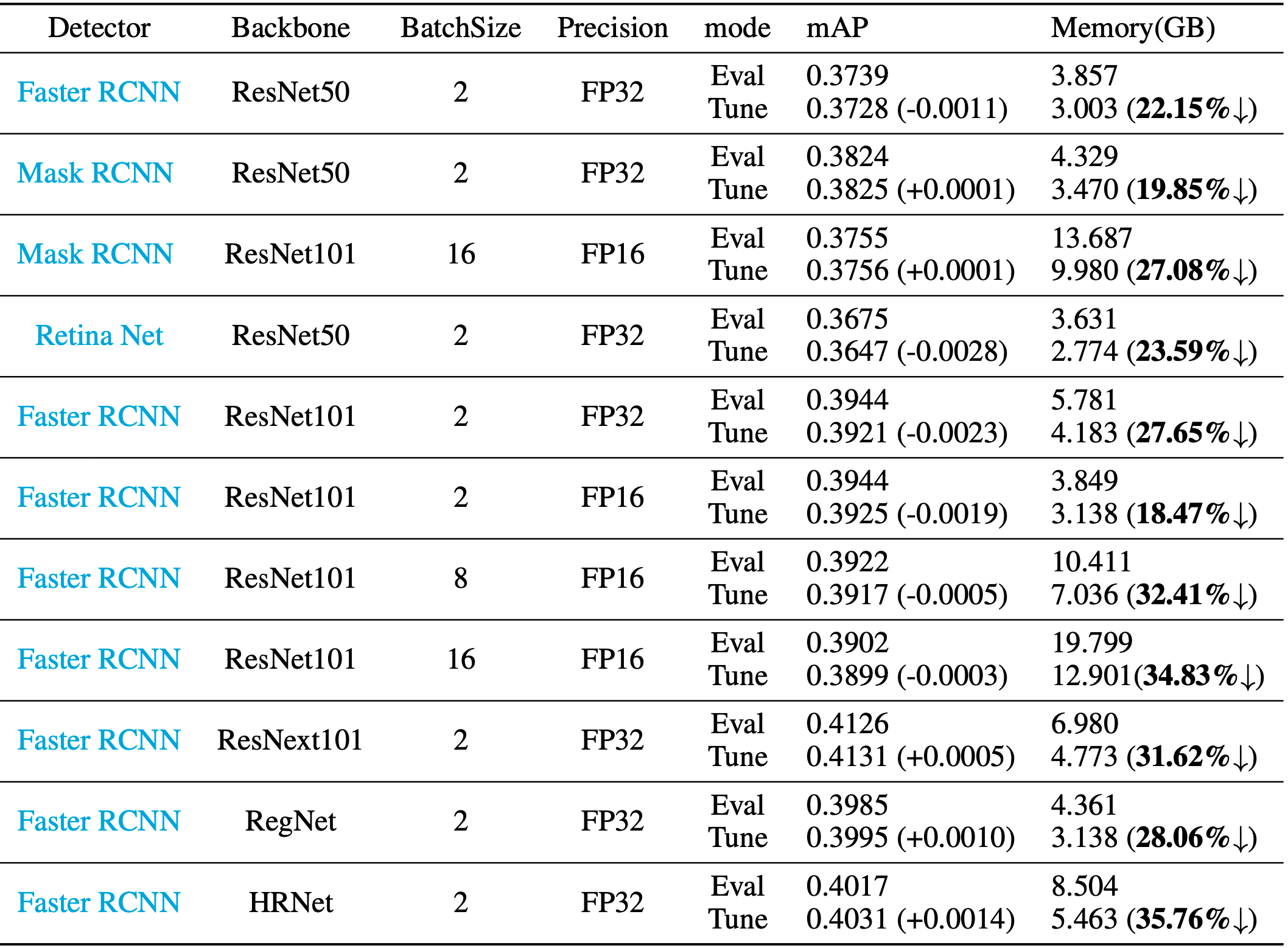
深度学习训练模型时,GPU显存不够怎么办?
近期发布的MMEngine v0.8.3版本中,包含了一项新功能,只需要在运行时加入一段命令行参数,MMDetection等下游代码即可 无损节省20%显存。用户只需要在训练脚本中加入--cfg-options efficient_conv_bn_eval="[backbone]"启动参数,即可启用该功能。下面是该功能在detection、classification任务上的加速效果实测,该功能在表格中称为“Tune Mode”。 这项功能的原理是什么?对什么样的模型有效果?如何使用这项功能?本文将从以上…

机器学习模型是否需要考虑变量共线性问题?
根据我自己做项目和写文章的经验来看,输入数据之间如果存在很强的共线性,通常会对传统的线性回归算法产生“毁灭级”的影响;对于一般的浅层机器学习算法,比如BPNN、SVM、随机森林(RF)、极限学习机(ELM)等,通常也会产生不可忽视的影响。 咱们首先统一思想,来明确一下变量之间多重共线性的含义: 如果某两个或多个解释变量之间出现了相关性,则称为多重共线性(Multicollinearity)。以下图为例 对于某一个以农业为主的小…