在将来的大模型发展中,大模型生成数据是否是解决高质量数据不足的方法,如果不是有什么方法解决数据不足?
当前的大模型通常指的是拥有数十亿甚至更多参数的预训练神经网络模型,在这个定义中有两个重要的关键点,一个是“数十亿以上的参数规模”,另一个是“预训练神经网络”。数十亿以上的参数规模意味着巨大的参数规模和夸张的算力要求,同时“预训练的神经网络”意味着需要庞大的数据和算力进行训练。所以这个定义很好的反映了大模型缩放定律的三个要素——算力、数据规模、参数规模。这三要素说明了,要训练好一个大模型,足够优质且庞大的数据集、足够大的参数量、和足够多的迭代次数缺一不可,当然更别提最基本的设备要求了。
大模型正在引领多个领域进入一个新的时代,在文本、视听、绘图、代码、社交等各个领域都有所建树,这也意味着,其背后所需要的数据集也千差万别。这也暗示着大模型三要素中,最难以获得的,就是足够优质且庞大的数据集了。能否获得数据集,反而才是训练或者微调一个大模型前,最需要考虑的问题。

这时就有人有这样的想法,既然大模型能力已经足够了,为什么不用大模型生成大量数据,来组成一个巨量的数据集,这样数据不足的问题不就解决了吗?
要考虑这个想法,首先需要回看大模型三要素中对数据集的要求——优质且大量。
显然,大模型批量生产的数据集满足了“大量”这个条件,但是,他真的优质吗?我们可以从通俗易懂的角度理解这个问题,当我们用一个大模型作为老师,他用自身所蕴含的知识去教导另外一个大模型学生去学习,学生大模型真能超过老师大模型的结果吗?这显而易见是很困难的,甚至说达到老师大模型同样的效果都很困难。老师大模型中产生的错误的结果,在学生大模型中就不可能得到正确的结果,这就是用模型生成数据集的局限性。
然而这个想法也并非一定是错误的,在某些情况下,由大模型生成的数据集还真能训练出一个超过老师大模型的模型。我们比较熟知的stable diffusion的应用中,就有这样一个例子。stable diffusion是一个文生图的模型,他本身并没有图像编辑的功能,现实世界中,对真实图像进行修改的数据集也少之又少,所以数据集问题成为训练一个图像编辑相关的大模型最大的问题。许多研究者另辟蹊径,在stable diffusion的基础上进行研究,得到了一种基于stable diffusion模型参数的图像编辑的方法——prompt to prompt。这个方法虽然不能对真实图像进行修改,但是他可以根据相近的两段文字来生成相近的两张图片。比如文字为“一张猫的图片”和“一张狗的图片”,这个方法可以生成两张图像,这两张图像除了猫和狗之外,其他背景部分高度相似。
这就意味着,虽然现在不能对给定的图像进行编辑,但是却可以利用prompt to prompt的思路和stable diffusion的编辑能力,去生成两个文本 “一张猫的图片”,“一张狗的图片”以及他们对应的,高度相似的两个图片。
Instructpix2pix的作者发现了这个角度,他选择把文本“一张猫的图片”放入gpt3中,获得指令文本“把猫换成狗”和编辑文本“一张狗的图片”。然后将指令文本和两张图片一起作为数据集,去训练一个全新的图像编辑模型。由于数据集的组成为:图片A,图片B(除了指令中提到的某个修改对象以外,其他部分和图片A高度相似),和指令文本,于是新的模型就获得了根据指令文本对原图像进行修改的能力。这也就意味着,模型加上特定的方法生成的数据集,确实能够填补特定数据集缺少的问题。

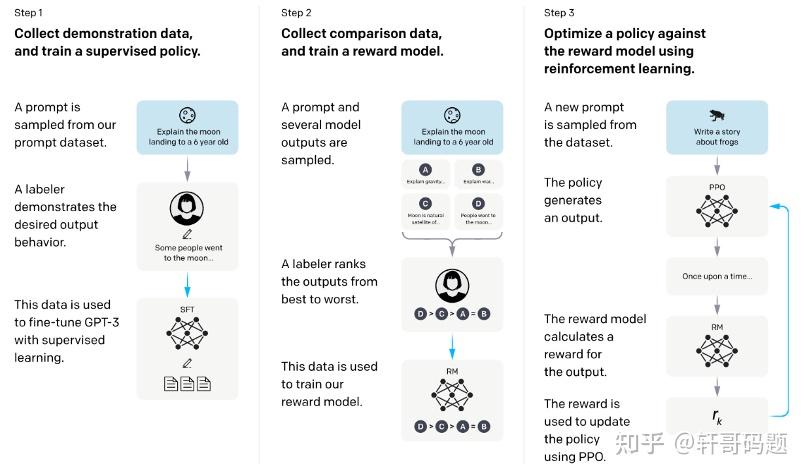
Chatgpt对应论文instructgpt中,还有一种对于大模型生成数据集而言更普适方法。简单来说,对于每个问题和问题的答案,先用人工评分的方式获得一个答案评分的数据,然后用这个数据训练了一个策略网络,这个策略网络可以给生成的答案进行评分。有了这个策略网络之后,再用模型针对每个问题生成大量答案,策略模型在对这些答案进行评分,当目标训练网络生成了策略网络认为好的答案的时候,评分就高,目标训练网络就更倾向于产生这种好的答案。在这个流程下,模型生成的答案,也成为了自己变好的途径。
但是同样的,凡事都有其局限性,这个流程中最重要的点就是策略网络的评分能力,策略网络的能力由人工评分的数据集决定,这个数据集的质量和数量是策略网络评分能力的最关键评判标准。于是兜兜转转,又回到了高质量数据集的获得问题之上了。
上文的两个例子均存在一些限制。尽管大型模型生成数据集的方法在某些情况下可以填补特定领域数据的不足,但其受到生成数据质量和多样性的制约,无法适用于所有领域。

数据的制约,也让很多大模型的应用陷入到了两难的境地。我们看到很多大厂纷纷成立了新型的数据标注基地,区别于以往的简单的数据标注,大模型的数据标注显然对标注员的文学素养、特定领域的知识沉淀有了更高的要求。
当然,也听说了一些“旁门左道”的方式。例如,将数据集构建的任务做成与用户互动的形式,例如让用户选择符合要求的验证码。通过设计这样的有趣的任务,让用户的参与辨认图像中的元素或回答问题,就可以在用户使用网络服务的同时,以分布式方式创建高质量的数据集。这种方法不仅可以解决数据不足问题,还能够培养用户参与数据集构建的积极性。但归根究底,这是一种无奈之举。