深度学习训练模型时,GPU显存不够怎么办?
近期发布的MMEngine v0.8.3版本中,包含了一项新功能,只需要在运行时加入一段命令行参数,MMDetection等下游代码即可无损节省20%显存。用户只需要在训练脚本中加入--cfg-options efficient_conv_bn_eval="[backbone]"启动参数,即可启用该功能。
下面是该功能在detection、classification任务上的加速效果实测,该功能在表格中称为“Tune Mode”。
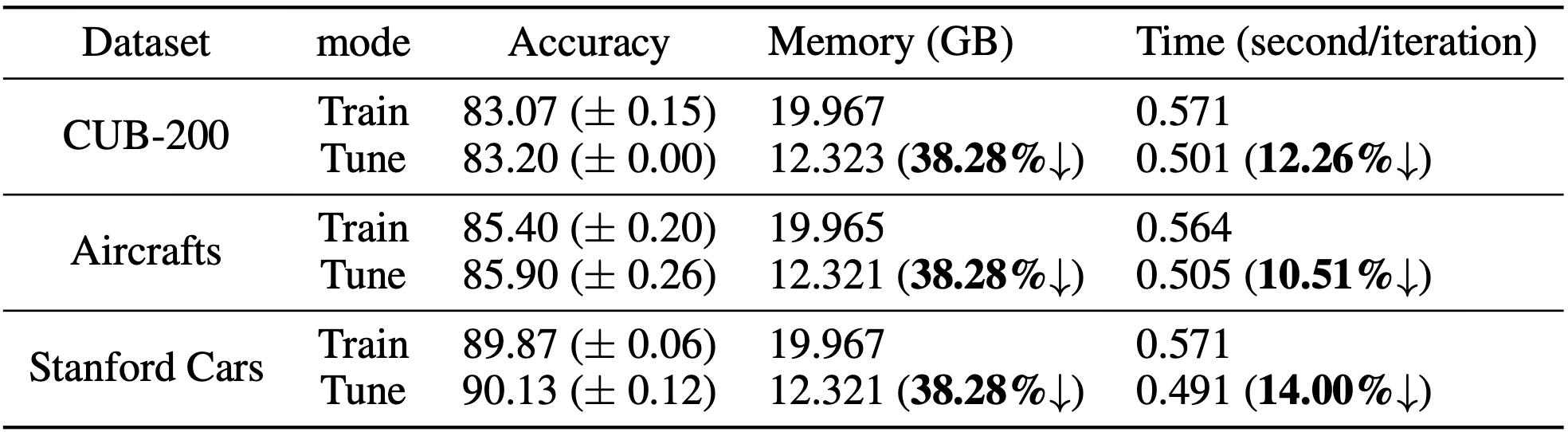
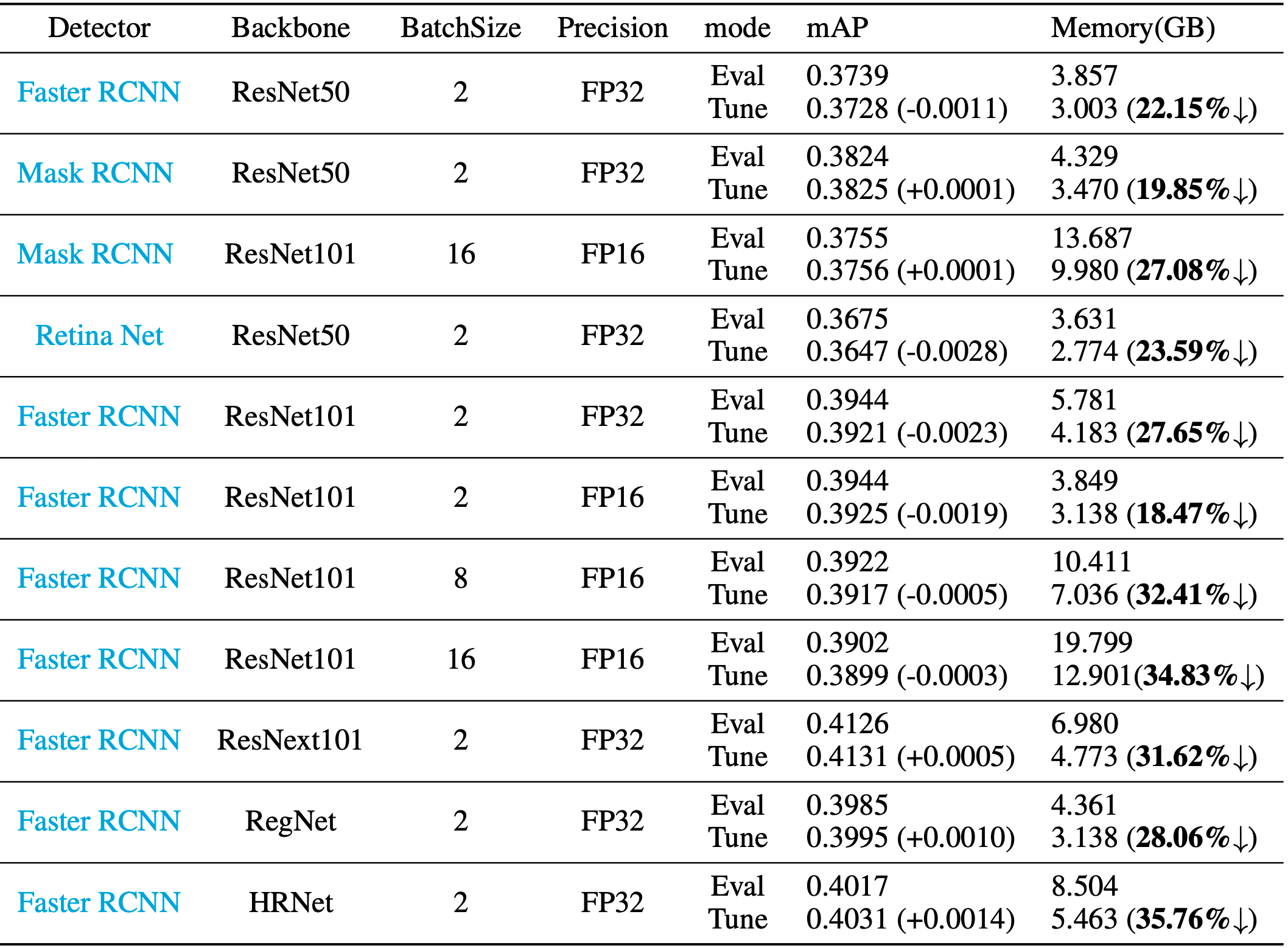
这项功能的原理是什么?对什么样的模型有效果?如何使用这项功能?本文将从以上角度对这项新功能进行解读,更多细节可参看论文《Tune-Mode ConvBN Blocks For Efficient Transfer Learning》。
卷积与批归一化模块的迁移学习
该功能瞄准的目标是一大类广泛使用的预训练模型:预训练卷积神经网络。为了方便说明,本文以目标检测这个具体任务为例,使用OpenMMLab出品的简单易用的MMDetection框架,其它任务也类似。
在卷积神经网络中,最常见的基础单元就是卷积-批归一化-激活函数,也即Conv-BN-Act Block。这其中,BN层最复杂:它具有两种不同的状态:在训练阶段(称之为Train Mode,对应于PyTorch代码中的nn.Module.train函数)会计算当前batch的统计量并更新内部统计量;在测试阶段(称之为Eval Mode,对应于PyTorch代码中的nn.Module.eval函数)则不用更新统计量。BN的一个广为人知的问题就是只适用于batchsize较大的情况,对于object detection这种非常占显存的任务很不友好。目前存在两种方式解决这个问题:
(1)使用多卡同步BN,把一台机器上八张卡的数据当做同一个batch来计算并更新统计量,这样可以增大batchsize,但是也因为多卡之间需要通信而显著拖慢训练速度;
(2)BN在训练阶段计算并更新统计量是为了使得训练变得稳定,那如果模型中的BN已经预训练过了,在微调阶段就可以固定统计量了。这一方法被称作norm_eval,在object detection领域有广泛使用。比如MMDetection里面的resnet类型的backbone代码,就有这一设置,即使在模型训练(微调)阶段也将BN的状态设置为Eval Mode。具体实现方式是重载train函数,保持BN模块为eval状态。
def train(self, mode=True):
"""Convert the model into training mode while keep normalization layer
freezed."""
super(ResNet, self).train(mode)
self._freeze_stages()
if mode and self.norm_eval:
for m in self.modules():
# trick: eval have effect on BatchNorm only
if isinstance(m, _BatchNorm):
m.eval()
根据统计,MMDetection里面有六百多个配置文件使用了预训练模型,而其中又有的模型使用了
norm_eval(具体统计数据见下图)。由此可见,在迁移学习中使用Eval Mode来进行训练,是一种普遍现象。
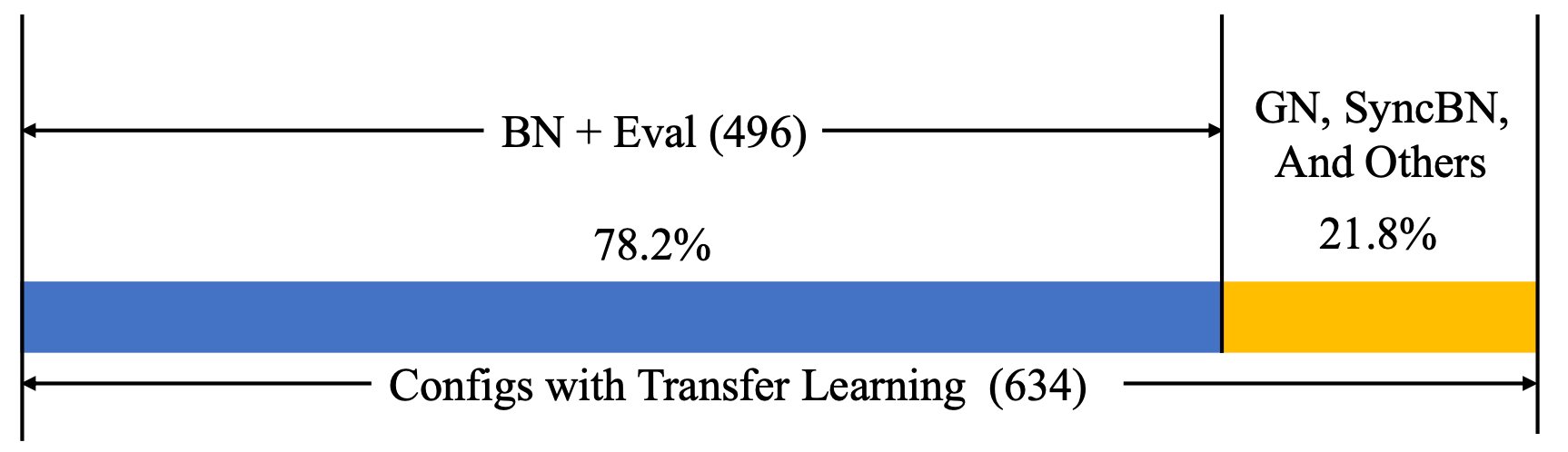
Eval模式下Conv-BN模块的显存占用分析
为了解决object detection显存占用高的痛点,结合《谁动了我的显存?——深度学习训练过程显存占用分析及优化》这篇技术博客中整理的显存占用细节分析,我们可以整理出Eval模式下Conv-BN模块具体占用了多少显存、为什么要占用这些显存。
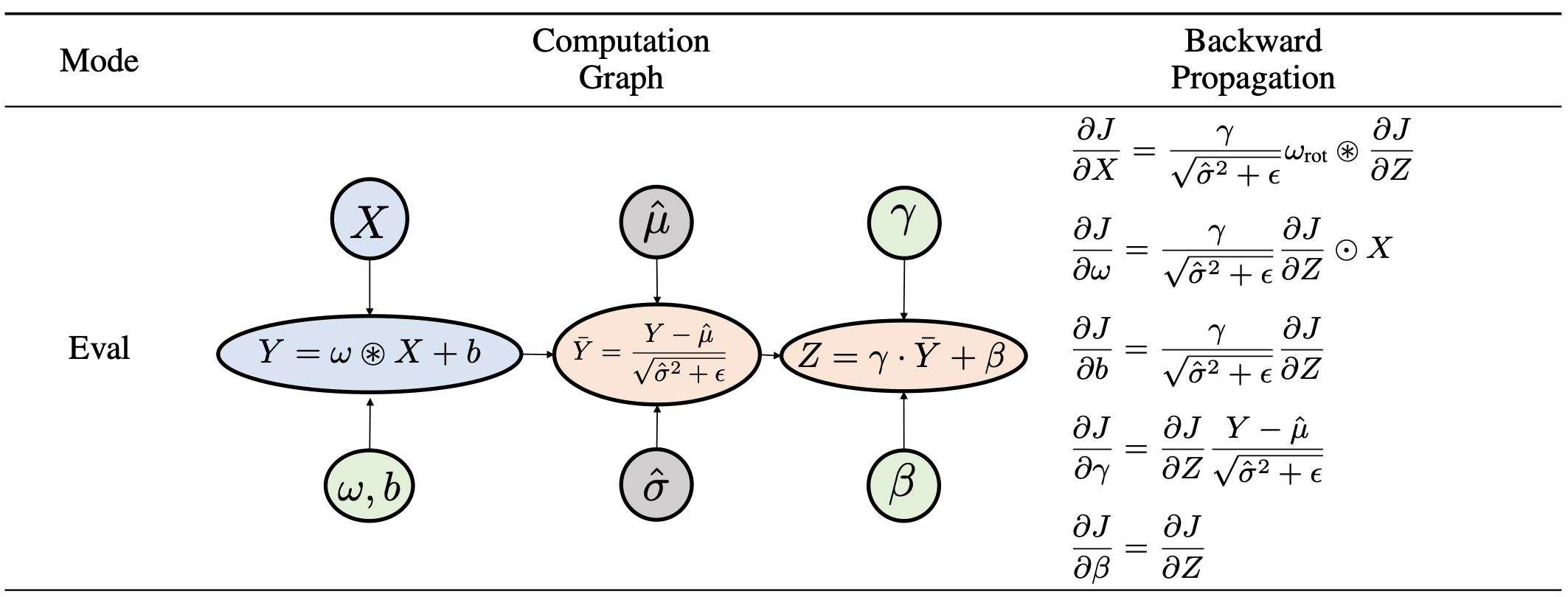
如上图所示,Eval模式下Conv-BN模块的输入为,可训练参数为卷积参数
及BN参数
。通过观察反向传播公式,我们发现:
计算的梯度并不需要用到中间变量,只需要保存输入
以及这些参数的值就可以了;唯一被保存下来的中间变量,就是卷积操作的输出
,而它只参与了
的梯度计算。
前向计算过程中,为计算反向传播而保留的中间变量,是模型训练过程中主要的显存占用开销。 上述分析表明,我们保存中间变量可以计算得到
的梯度;而保存中间变量
只是为了计算
的梯度,非常不值得(
是卷积层的输出,一般都很大;
作为BN层的参数,一般都很小)。是否能够对此进行一些优化呢?
Detectron2的解决方案:冻结BN的全部参数
既然计算的梯度非常不值得,那么只要我们进一步把
都冻结、不需要计算梯度,那么就不需要计算
的梯度,也就不需要保存中间变量
了。
这一方案正是知名object detection框架Detectron2采用的FrozenBatchNorm2d方案。然而,它的缺点在于减少了模型的关键模块(BN层)的可训练参数,对于object detection的训练效果(mAP指标)有显著影响。
值得借鉴的思想:Conv-BN的部署模式(Deploy Mode)
BN模块被广泛应用的一个重要原因,就是Conv-BN两层可以在部署时合并成一个层,这被称为部署模式(Deploy Mode)。具体来说,卷积与乘法具有结合律:先卷积后乘法等价于先对卷积核做乘法、再用变换后的卷积核做卷积(也即)。因此,在部署阶段,当模型不再需要训练时,我们可以把BN的全部参数都融合到卷积层的参数中,提前计算新的卷积参数,从而用一次卷积运算实现卷积与BN两步运算的效果。
如果我们把这一部署模式拿来训练,其对应的计算图与反向传播公式如下图所示:
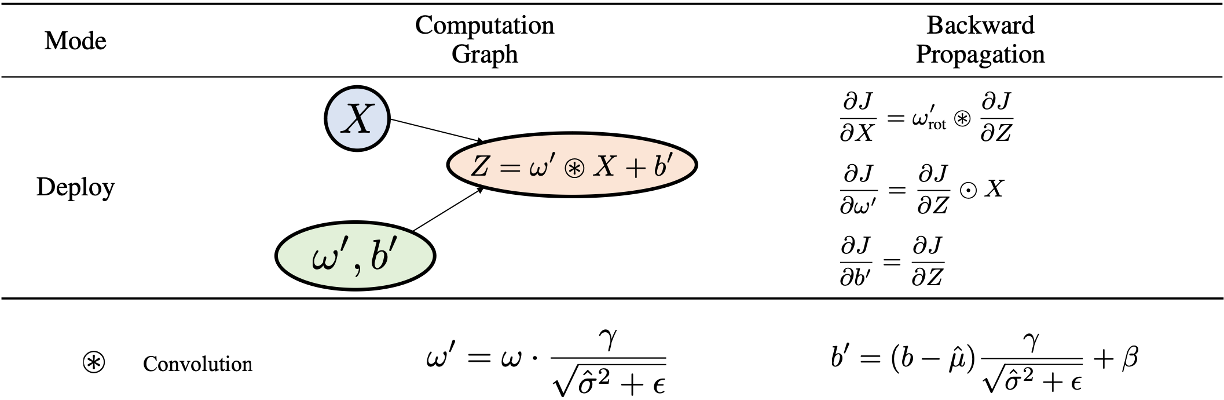
这样就不需要保存中间变量了,Deploy Mode可以减小显存占用。然而,与FrozenBatchNorm2d一样,它也使得BN层的参数无法被训练,会影响模型训练效果。
Deploy Mode用于训练的另一个问题,是直接对权重操作带来的梯度不稳定性。 对比Eval Mode,我们可以发现:Deploy Mode与Eval Mode的前向计算结果是等价的,但是反向传播得到的梯度结果存在倍数关系:Deploy Mode的卷积核参数是Eval Mode的卷积核参数
的
倍,而前者的梯度
是后者梯度
的
倍,两个倍数之间存在倒数关系。如果
,那就意味着使用Deploy Mode训练时,参数值相比于Eval Mode缩小了100倍,而梯度则会扩大100倍!这一结果表明,只要
的值偏离
,Deploy Mode用于训练就会导致不稳定,极大地影响模型的训练效果。
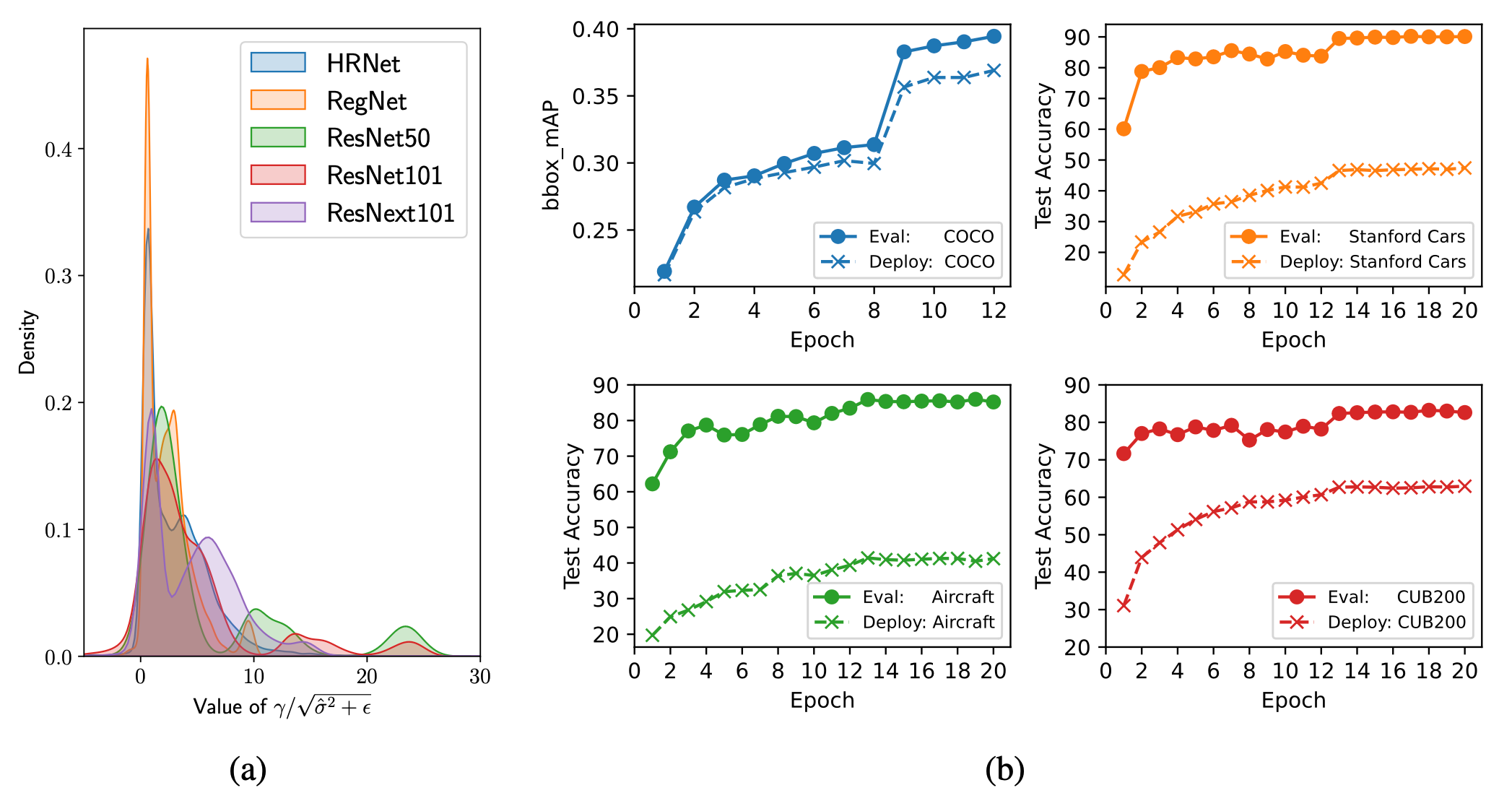
下图中,左图统计了常用的预训练模型中值的分布,右图对比了四个训练任务中Deploy Mode与Eval Mode的训练准确率对比。从这些实验结果中,我们可以看到:
的值偏离
是非常常见的,使用Deploy Mode训练确实会显著降低模型训练精度。
解决方案:专门用于微调的Tune Mode
为了解决上述问题,提高迁移学习的效率,我们为Conv-BN模块专门设计了一种新的计算方式,称之为微调模式(Tune Mode):将BN层作用在卷积核上。其具体计算图及反向传播过程见下图:
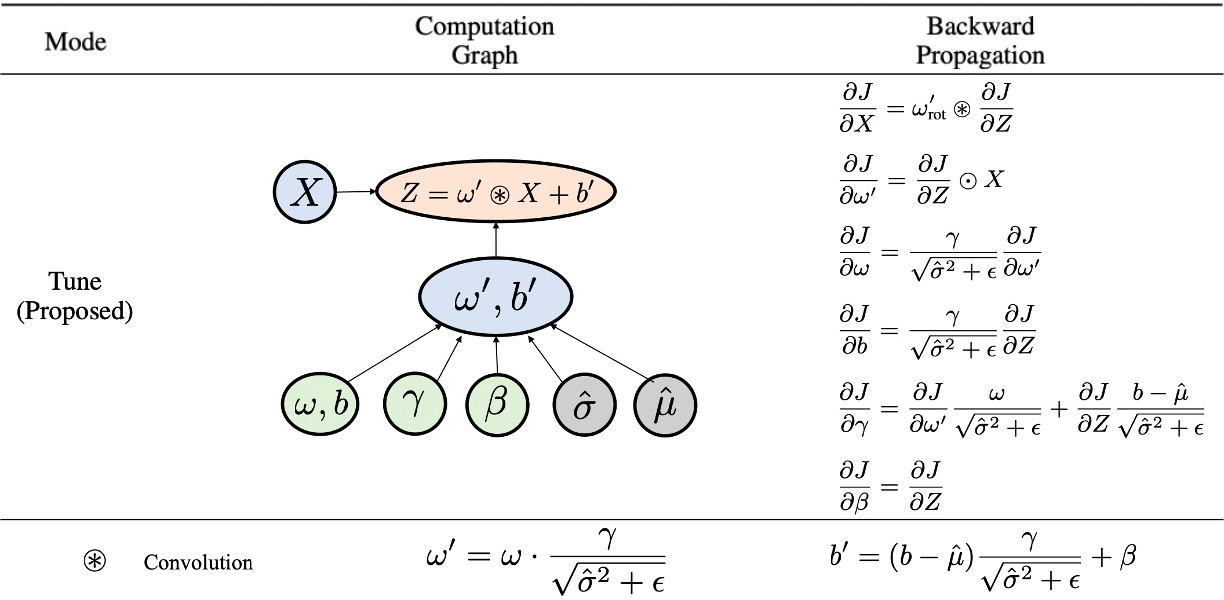
该模式具有两个显著优点:
(1)它的前向传播与反向传播过程与Eval Mode完全等价,因此不存在Deploy Mode的训练不稳定的问题。
(2)因为将BN操作放在了卷积核上,其反向传播过程中记录的中间变量仅为变换操作之后的卷积核与
,计算速度与显存占用均显著优于Eval Mode。
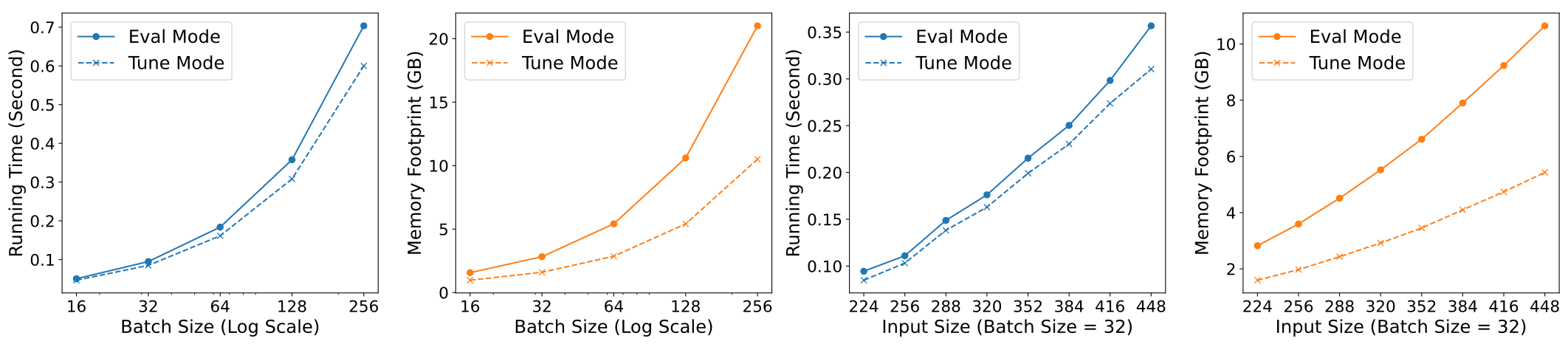
如上图所示,在各种输入配置下,Tune Mode均比Eval Mode更快,而且显存占用更小。
对Eval Mode、Deploy Mode、Tune Mode三种模式总结如下:
在训练稳定性方面,Deploy Mode Tune Mode
Eval Mode。
在训练效率方面,Eval Mode Tune Mode
Deploy Mode
因此,只要有用到Eval Mode进行训练的地方,就可以替换成Tune Mode,无缝享受训练提速、显存占用降低的好处。
实现方案:自动计算图捕获、无需修改代码
Tune Mode的思想很简洁,然而,由于PyTorch使用的是动态图,用户的代码里使用Conv与BN的方式可能五花八门。例如下面这个神经网络,也是一段可以运行的PyTorch代码,然而其中配对的Conv-BN调用模式非常复杂:
(1)SubNet1中的self.bn1(self.conv1(x))是一对连续的Conv-BN调用,比较容易发现,可以优化成Tune Mode。
(2)SubNet1中的self.bn2(self.conv2(self.conv2(x))),只有self.conv2的第二次调用能够与self.bn2构成一对连续的Conv-BN调用,第一次self.conv2调用无法优化。
(3)SubNet1中的self.conv3(x)与SubNet2中的self.bn3(self.bn3(x))调用中的第一次bn调用构成一对连续的Conv-BN调用,但第二次self.bn3调用无法优化,且能优化的Conv-BN对跨越了两个模块(SubNet1与SubNet2)。
class SubNet1(nn.Module):
def __init__(self, *args, **kwargs) -> None:
super().__init__(*args, **kwargs)
self.conv1 = nn.Conv2d(6, 6, 6)
self.conv2 = nn.Conv2d(6, 6, 6)
self.conv3 = nn.Conv2d(6, 6, 6)
self.bn1 = nn.BatchNorm2d(6)
self.bn2 = nn.BatchNorm2d(6)
def forward(self, x):
x = self.bn1(self.conv1(x))
x = self.bn2(self.conv2(self.conv2(x)))
x = self.conv3(x)
return x
class SubNet2(nn.Module):
def __init__(self, *args, **kwargs) -> None:
super().__init__(*args, **kwargs)
self.bn3 = nn.BatchNorm2d(6)
def forward(self, x):
x = self.bn3(self.bn3(x))
return x
class Net(nn.Module):
def __init__(self, *args, **kwargs) -> None:
super().__init__(*args, **kwargs)
self.net1 = SubNet1()
self.net2 = SubNet2()
def forward(self, x):
x = self.net2(self.net1(x))
return x
如果我们只是实现了一个高效的Conv-BN Tune Mode调用函数tune_mode(conv, bn, x),那每个用户将需要花费相当多精力来调试、查找、修改代码,在合适的地方插入我们的代码,才能享受到Tune Mode的好处。
幸运的是,近年来PyTorch代码编译器的发展,已经使得我们可以直接捕获计算图(具体参见博客《PyTorch 2.0 编译基础设施解读——计算图捕获(Graph Capture)》),并且在计算图上进行操作。
于是,借助PyTorch编译器,我们实现了一个turn_on_efficient_conv_bn_eval_for_single_model(net)函数,只需要把整个模型交给这个函数,它就能自动分析里面的代码与计算图、找到可以优化的相邻Conv与BN调用,并自动将其转成高效的Tune Mode实现。
使用方法
这一函数已经整合进入了OpenMMLab的训练引擎MMEngine(自v0.8.3版本开始),意味着所有使用MMEngine进行训练的代码都可以无缝享受这一加速,只需要在训练脚本中加入配置--cfg-options efficient_conv_bn_eval="[backbone]",即可立刻降低显存占用,实测能降低左右的显存占用。没有使用MMEngine的朋友,也可以直接使用我们开源的代码,手动加入一行
turn_on_efficient_conv_bn_eval_for_single_model(net)函数即可。
目前我们使用的是torch.fx进行计算图捕获,只能捕获backbone模块的计算图,还不能捕获detector的全部计算图。但由于object detection里面主要使用迁移学习的模块就是backbone部分,因此torch.fx能够处理绝大多数情况。未来,我们将借助PyTorch 2.0强大的TorchDynamo模块进行更加充分、安全的计算图捕获。目前,这个提案已经提交给了PyTorch团队,未来有望成为PyTorch 2.0torch.compile函数内置的优化功能之一。
总结
如果你的模型训练过程中使用了卷积层与处于Eval Mode的BN层,那么你可以从我们的方法中受益。为相邻的卷积与BN开启微调模式,即可享受计算加速、显存优化。
我们在detection实验、classification实验等广泛的实验中进行了验证,均观察到了明显的优化效果。原来需要V100(16GB显存)才能做的实验,现在可以用更便宜的RTX 3080 (12GB显存),或者可以用更大的batchsize、同样的时间可以跑更多的实验。
欢迎大家试用这一新功能,大家可以将使用体验反馈在这里。目前这一功能刚发布不久,需要手动启用,但是如果社区反馈较好,我们也可以把这一功能变成默认功能。目前能确定的是:Conv+Eval Mode BN一定能无损加速;但如果原来的训练模式是Conv+Train Mode BN,需要先切换成Eval Mode确认是否会影响精度。如果切换成Eval Mode之后不影响精度,那也可以无损加速。至于具体哪些模型的训练可以将Train Mode切换为Eval Mode,有待未来的研究进一步揭晓。
最后,感谢OpenMMLab的MMCV、MMEngine、MMDetection团队在整合过程中提供的技术支持。
心动不如行动,大家一起来试用吧