机器学习模型是否需要考虑变量共线性问题?
根据我自己做项目和写文章的经验来看,输入数据之间如果存在很强的共线性,通常会对传统的线性回归算法产生“毁灭级”的影响;对于一般的浅层机器学习算法,比如BPNN、SVM、随机森林(RF)、极限学习机(ELM)等,通常也会产生不可忽视的影响。
咱们首先统一思想,来明确一下变量之间多重共线性的含义:
如果某两个或多个解释变量之间出现了相关性,则称为多重共线性(Multicollinearity)。以下图为例
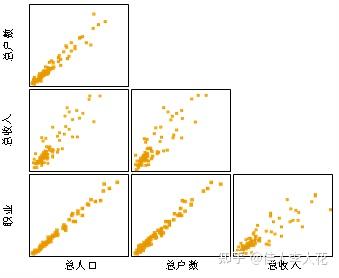
对于某一个以农业为主的小区域来说,总人口与总户数、总人口与职业、总户数与职业之间,存在着极强的相关性。
如果以人口、户数和职业三个变量作为输入变量,构建回归模型预测总收入的话,可能会得到一个β1人口+β2户数+β3职业=收入的拟合公式。
但是由于输入变量间存在着人口=λ收入=σ户数的线性关系,因此拟合公式中的系数β1,β2,β3可能会失去本该具有的意义,变得无法解释,甚至出现“常理”本该为“正”的系数变成了“负”数的情况,导致拟合公式失效、将真正重要的解释变量排除在外、参数估计值的方差变大等问题,造成依据统计模型做出的预测无法给出有用的信息。
而对于浅层机器学习算法来说,如果数据间虽然有共线性,但程度比较弱的话,可能不会对结果产生影响;但是如果像上图那样,存在严重的共线性问题时,则同样会导致分析结果不稳定,回归系数难以解释,甚至正负性与实际相反的情况。
而面对多重共线性的问题时,一般有以下几种解决方案:
1、手动移除出共线性的变量
顾名思义,就是精简数据,不要贪多求全,主动删除一些“不必要的”输入数据。这种方法可以通过事先对输入变量进行相关性分析,一旦发现有两个相关系数很大的变量,即选择手动移除一个,然后再进行回归分析。
但是这种简单粗暴的删除变量法,却非常容易损失重要信息,或者盲目删除了重要变量。因为虽然两个变量之间相关性很大,但那一点点不相关的特征可能恰恰是对结果影响最大的信息,所以需要“慎之又慎”的进行应用。
2、逐步回归法
这是目前最为常用的方法之一,让系统自动进行自变量的选择剔除,使用前进法或后退法将共线性的自变量自动剔除出去。
但是无论使用哪种方法进行变量剔除,都可能丢失本不想删除的变量,或让某些含有重要信息的变量成为“漏网之鱼”,影响回归模型的预测效果。
3、增加样本容量
对于我们这些以数据为生的人来说,这种解决方法犹如废话一般,毕竟如果有条件收集到更多的数据,没有人会主动把送上门的数据扔出门外……

面对这些“聊胜于无”的数据前处理方法,1962年提出的“岭回归法”至今仍是解决多重共线性的首推方法。
该方法得到的回归系数虽然往往更接近真实的情况,但是可能却会以损失一部分预测精度作为代价。
那么,真的没有其他更好的方法可以进行尝试了吗?
自从大模型横空出世以后,答案是“NO”!
我们完全可以把这个问题交给ChatGPT去头疼——

它会“尽己所能”的帮我们提出一些解决方案和方法。可是如果想进一步获得一些有针对性的可执行程序,便不能这样“简单直接”的进行询问了,毕竟ChatGPT认为自己是一个“文本模型”,并不能直接编写程序或者分析数据。
那么,这种时候,学习一些大模型的专用“咒语”,就显得十分必要和有效。像我这种以数据分析为生,却只具备半吊子编程能力的科研人员,其实只需要学习一些入门级的课程,了解各种大模型的基本功能,掌握常见的prompt,就可以借助大模型的力量,优化数据的处理过程。「知乎知学堂」联合「AGI课堂」推出的【程序员的AI大模型进阶之旅】的课程安排就非常合理,很适合新手入门了解,一共2天的课程,邀请了圈内技术大佬全面解读前沿技术,能够有效帮助编程小白快速提升认知和技术能力。
我相信通过学习这些课程,萌新的程序猿小伙伴们,再看到诸如t-SNE,Isomap,Sparse Coding和Denoising Autoencoder之类的“炫酷”数据前处理方法,就不会再觉得“高不可攀”,不会觉得恐惧和难以靠近,而是可以轻松的直接进行应用。
比如,我将需要分析的数据交给ChatGPT,“吩咐”它使用Denoising Autoencoder方法处理输入数据:
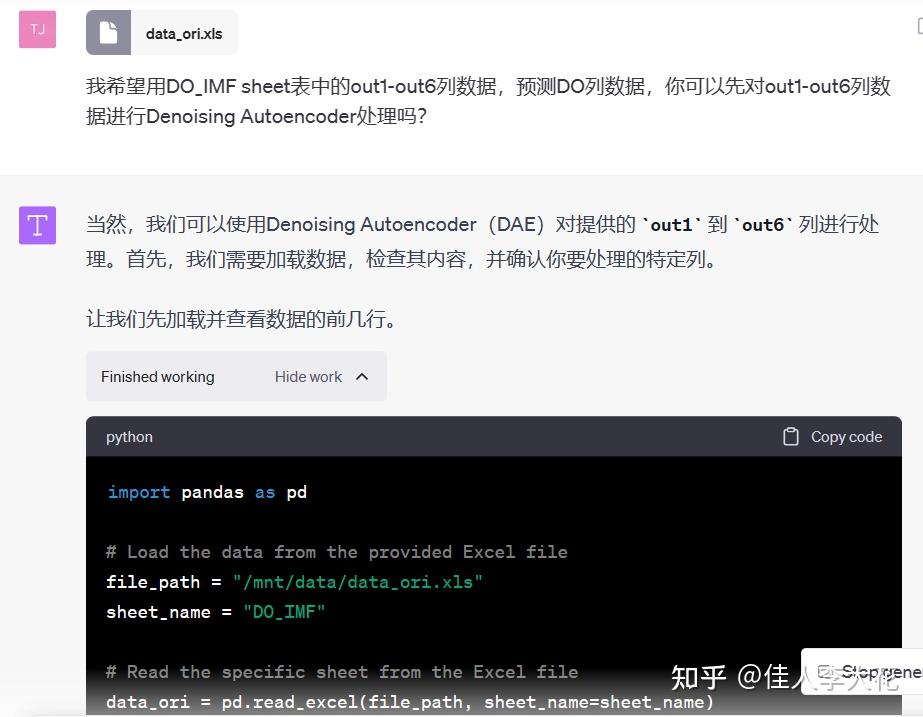
囿于目前的算力所限,它无法在线进行处理和计算,因此它会直接输出一段基于Python的可执行代码——
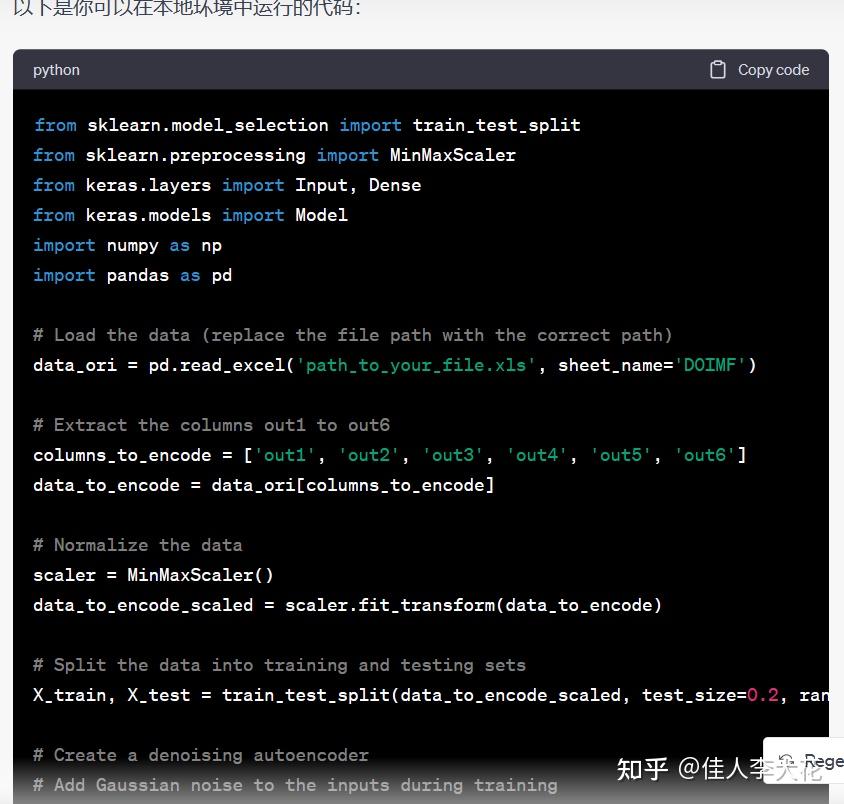
只需要根据文件所在的本地地址,更新path,便可以成功运行程序。
当然,我觉得这段程序算是ChatGPT的“超常”发挥,目前它完成的本地程序中,不报错的概率比较低,需要应用一些调试程序的“咒语”,才能修改程序中的所有bug,实现程序的成功运行。
但是相比于从零开始编写程序,或者从Github上下载相关的程序段,“艰难”的进行纠错和调试,ChatGPT帮助完成的程序段属于原创,而且因为这是它针对你的需求为你量身定制的个性化程序,其完成度和准确性应该会优于现存的所有程序论坛。
随着我们逐步迈进大数据时代,未来需要处理的数据量会呈现指数级增加。到了那个时候,线性回归模型和浅层机器学习算法,可能都不再适用,深度学习算法才是“王道”。
那么输入数据的共线性对于深度学习是否还会造成困扰呢?这是ChatGPT的回答——

从Chat的回答,以及我自己的一些实践经验来看,一般程度的多重共线性通常不会对深度学习造成影响。但是如果共线性过强,或者多个变量间均存在显著共线性,可能会影响模型的解释性、造成模型的过拟合,甚至影响训练过程的稳定性和收敛速度,我就曾经遇到过一次多重共线性引发的梯度消失情况……
当然,这种问题可能会随着机器学习模型本身的发展进步而得到解决,毕竟从“理论”上来说,“完美”的模型应该是可以hold住多重共线性问题的。但是应该的事情多了,模型效果才是王道。至少从现阶段来看,各种数据前处理仍然是机器学习相关论文的重要内容。
因此,不管是你是搬砖程序员还是萌新研究生,要用机器学习做项目、写文章,通过阅读文献,了解最新的数据前处理方法,恐怕是不可缺少的重要内容。而借助大模型的神秘力量,或许可以帮你轻松实现对这些最前沿方法的理解与应用。
虽然“完美”机器学习模型理论上可以自发解决变量共线性问题,但基于现阶段的现实考量,在数据、算力和模型本身都还不那么“完美”的情况下,充分提取输入数据中的有效信息,抛弃冗余信息,降低数据维度,对于提升机器学习乃至深度学习算法的训练精度和泛化能力,或许有着不可预估的神秘力量!
