2023年,Chatgpt、Midjourney等AI人工智能在你周围产生了哪些切实的影响?
Midjourney 我除了尝鲜用得不多,但 ChatGPT 我是离不开了,特别是翻译润色和写代码的功能。今天给大家带来一篇干货:如何用 ChatGPT 自动编写爬虫代码。
课前思考题:如果要抓取一份博客文章的清单,并进行数据分析,需要什么步骤?花费多长时间?
省流:本文介绍了如何将网络请求导出为 HAR 文件后上传至 ChatGPT Code Interpreter 插件,并通过相应的 Prompt 要求 ChatGPT 自主完成爬虫代码的编写。
前言
我们都知道,ChatGPT 的代码能力很强,可以在对话中理解需求并反复修改代码细节,从而帮助不那么懂编程的朋友编写一些简单的代码片段(snippet)甚至完整的代码。
之前也看到过一些使用 ChatGPT 来编写爬虫代码的分享,但说实话,效果都不理想,基本上就是从 Github 粘贴了一些代码示例,爬虫代码的特性决定了,只要目标网站的源码结构稍有修改,就可能导致爬虫代码不再适用。ChatGPT 略显陈旧的离线知识库与爬虫代码所要求这种时效性显然是不那么匹配的。
不过,方法总比困难多,还是可以尝试克服一下的…
什么年代了,还在手写爬虫.jpg
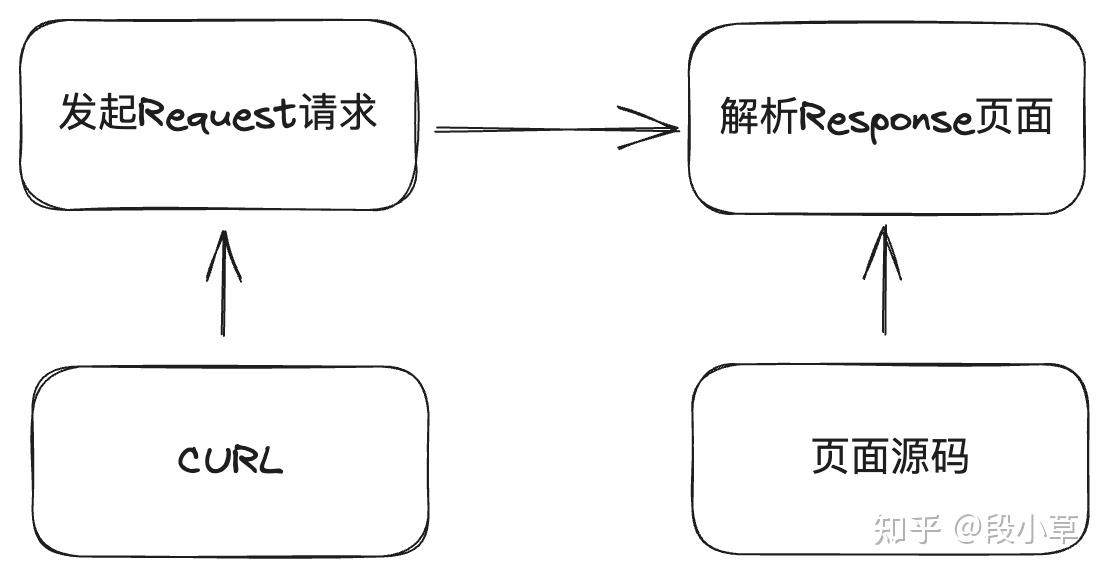
所谓爬虫,就是用代码去自动化地访问网页并从网页源代码中提取出需要的内容,加上一些前后的处理,可以大概理解为以下过程:分析需求→逆向 JavaScript → 发起 Request 请求 → 解析 Response 页面 → 存储结果。

其中最核心的步骤的就两步:发起 Request 请求 → 解析 Response 页面。
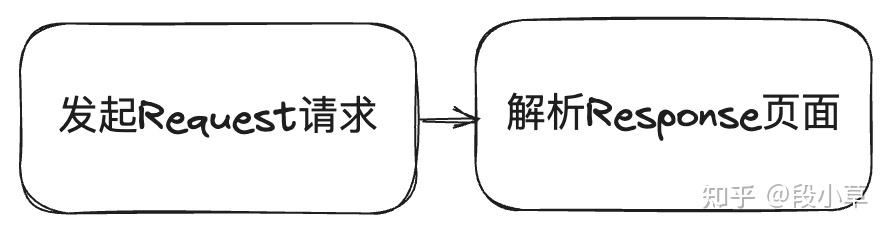
一般情况下,我们的入口只是一个 URL 链接。在写爬虫代码的过程中,我们可以使用浏览器的开发者工具/抓包软件来拦截请求过程,找到返回内容。
但由于安全限制,ChatGPT 默认不能联网;如果依托插件进行「联网」,相当于插件开发者作为中转站,将网页信息格式化后提供给 ChatGPT 使用,那么 ChatGPT 看到的,依然不是页面源码。所以我们如果仅仅提供给 ChatGPT 一个网页链接,它并不能有效地分析请求和返回,或者说,即便它给出了一部分代码,也是因为它的训练内容(截止2021年9月)中曾经有过类似的 URL,但大概率是过时或者不能用的。
我们这次先选一个比较简单的例子,只要学过一点点爬虫的新手就能完成,Sam Altman 的博客:https://blog.samaltman.com/?page=1
这个博客的页面结构很简单:通过page参数翻页,每页上有10篇文章,我希望获取到文章标题、文章链接、发布时间、点赞数。
我们先尝试问一下 ChatGPT,看它的知识库中有没有现成的代码(同时排除它直接抄答案的嫌疑):
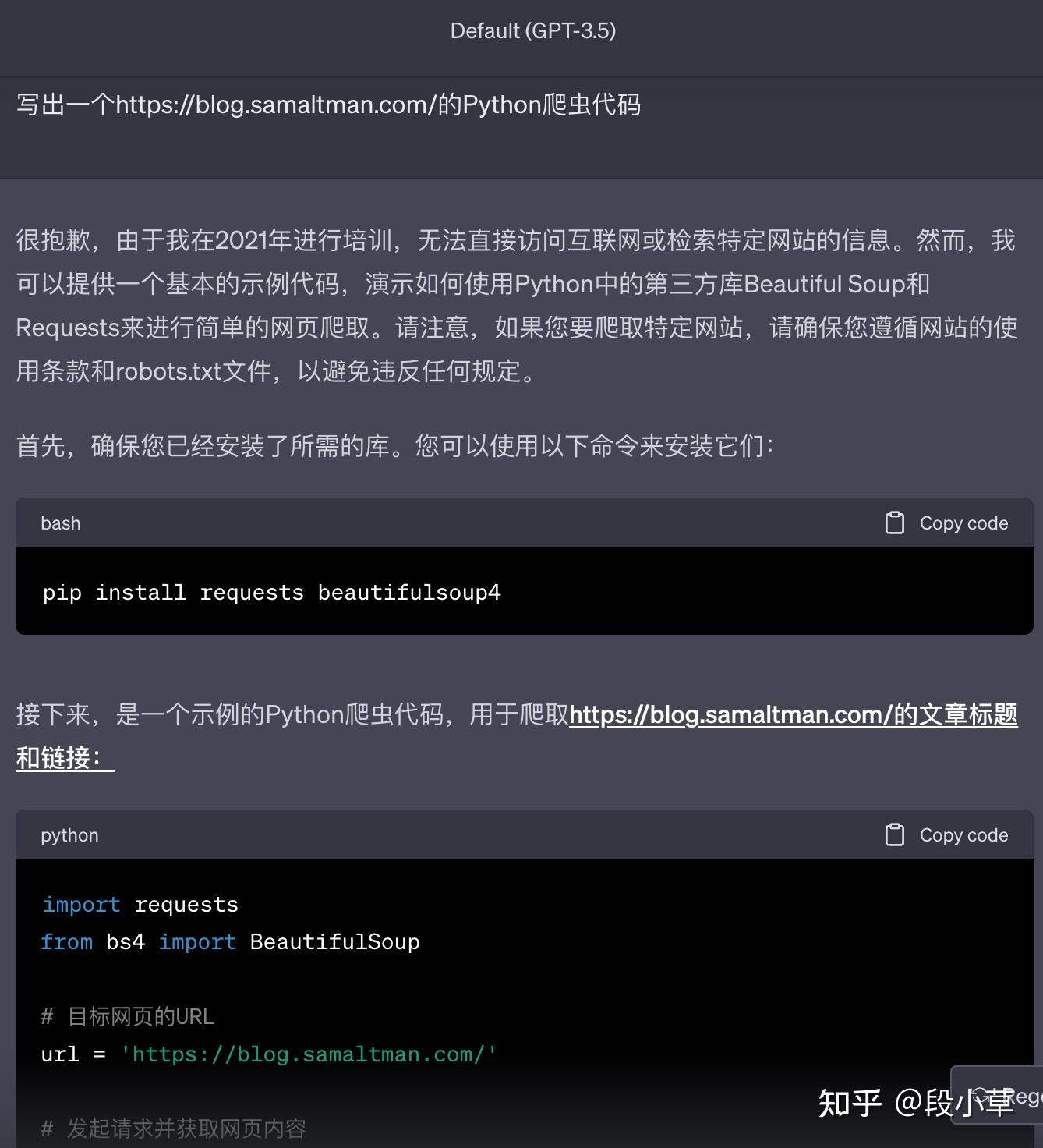
实际上,不论是 GPT-3.5 还是 GPT-4,都不能给出正确回答(意料之中),不过 GPT-4 写的代码会修改 UA 并处理 status_code,看上去更完整一些。
既然默认情况做不到,接下来就需要提供更多必要的信息了,回到刚才的两个步骤,既然 ChatGPT 自己不能联网,我们就把请求体和返回内容直接告诉它:
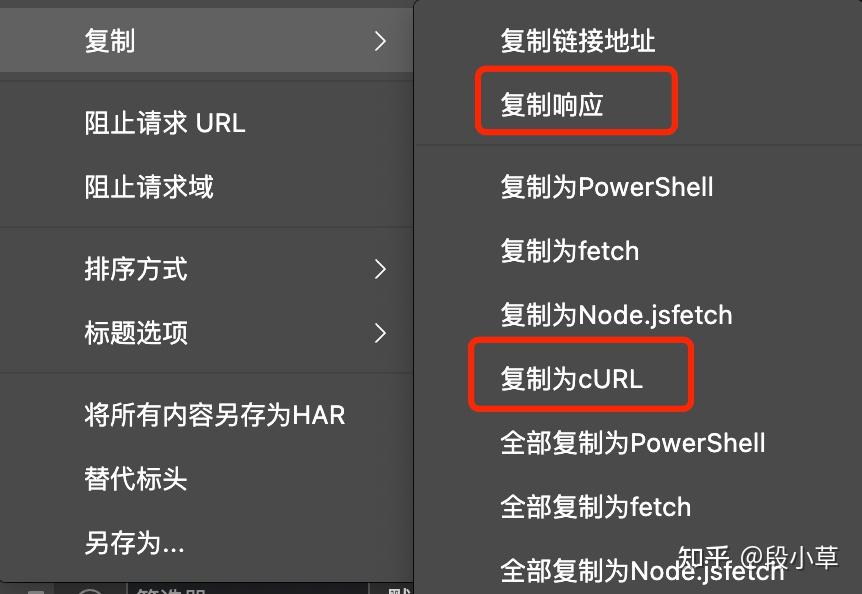
在开发者工具的 Network 页面中,选择一条请求:
然后尝试一下:
我会给出一个网页的CURL和返回的源码,请写出一段Python爬虫代码,用于访问并获取页面中的文章标题、链接、发布时间:
# 省略粘贴的 CURL 和页面源码

emmmmm,那就只能(挑一下)粘贴其中一部分了,这次基本能得到正确答案:
import requests
from bs4 import BeautifulSoup
url = "https://blog.samaltman.com/?page=1"
headers = {
"authority": "blog.samaltman.com",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"cache-control": "max-age=0",
"sec-ch-ua": "\"Not/A)Brand\";v=\"99\", \"Microsoft Edge\";v=\"115\", \"Chromium\";v=\"115\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"macOS\"",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "none",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36 Edg/115.0.1901.203",
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
# Extracting the article details
article = soup.find('article', class_='post')
title = article.find('h2').text.strip()
link = article.find('h2').a['href']
date = article.find('span', class_='posthaven-formatted-date').text
print(f"Title: {title}")
print(f"Link: {link}")
print(f"Date Published: {date}")
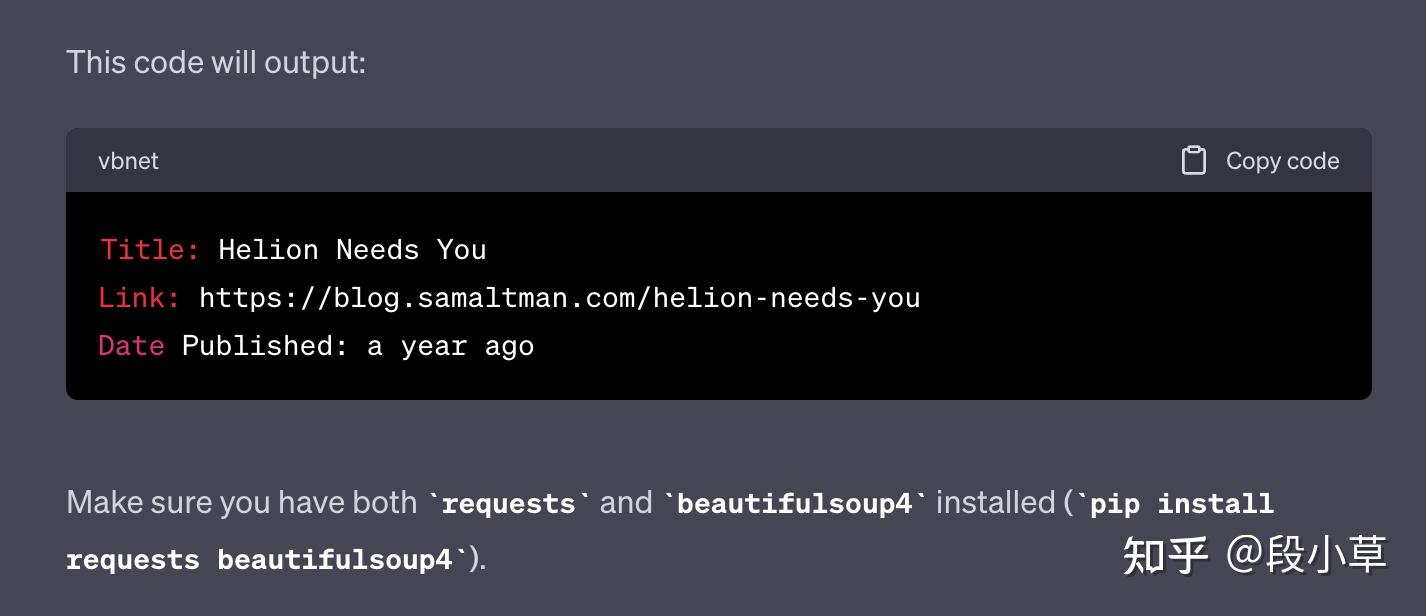
也就是说,如果把 CURL(请求体)和返回的页面源代码都交给 ChatGPT,它是能自己解析结构并写出正确的爬虫代码的。只不过这样的做法不怎么优雅,有这手动挑选+复制粘贴功夫自己都能写完了。
等等,那有没有不复制粘贴的法子?
HAR 文件:浏览器请求日志
HAR = HTTP Archive,其实就是浏览器在加载页面时与服务器之间的所有网络交互的详细日志。
当我们在浏览器里输入一个网址并按下回车,浏览器并不只是请求了那个网页,实际上,它可能还请求了许多其他的资源,如图片、视频、CSS 样式表、JavaScript 脚本等。这些请求和它们的响应组合起来,构成了我们在浏览器上看到的完整网页内容。
HAR 文件就像一个录制了这些请求和响应的「录像带」。它可以告诉我们:
- 请求的顺序。
- 每个请求的URL地址。
- 请求和响应的头部信息。
- 请求所花费的时间。
- 以及其他与网络请求相关的信息。
也就是说,当我们导出一个 HAR 文件的时候,几乎就是一次性导出了浏览器开发者工具 Network 页面中记录的所有信息。

HAR 文件听上去神秘,但其实就是一个 JSON 文件,比如:
{
"log": {
"version": "1.2",
"creator": {
"name": "Browser",
"version": "XX"
},
"entries": [
{
"startedDateTime": "2023-08-20T12:00:00.000Z",
"time": 100,
"request": {
"method": "GET",
"url": "https://example.com",
// ...
},
"response": {
"status": 200,
"content": {
"text": "..."
},
// ...
}
},
// More entries...
]
}
}
从上面的示例中可以看出,HAR 文件的主要结构包括:
- log:这是文件的顶级对象,包含了与该记录相关的所有数据。
- version:描述了 HAR 规格的版本。
- creator:描述了创建 HAR 日志的应用程序或工具的信息。
- entries:这是 HAR 文件中最重要的部分,包含了所有的网络请求和响应。每个条目描述了一个单独的请求,包括 URL、请求方法、请求头、响应头、响应状态码、响应体大小等。
- browser:(可选) 描述了执行记录的浏览器信息。
也正因有了 HAR 文件,我们不必要再人工筛选请求,再手动多次复制粘贴,导出导入一把梭就好了。
(使用 HAR 还有一个好处,就是 HAR 是包括了 JavaScript 文件的,在一些情况下能用到…)
实战:Code Interpreter 与 HAR 文件的碰撞
还是刚才的例子,我们打开 Sam Altman 的博客,在浏览器控制台中导出 HAR 文件:

将这份文件上传到 ChatGPT Code Interpreter,之后的 Prompt 大家可以自己尝试。
我测试了两种 Prompt,前者主打一手信任,ChatGPT 会的比我多多了,我哪有什么资格指手画脚,一切你说了算你看着办:

后者则给出了详细的步骤和需求,甚至用上了魔法提示词 step-by-step:
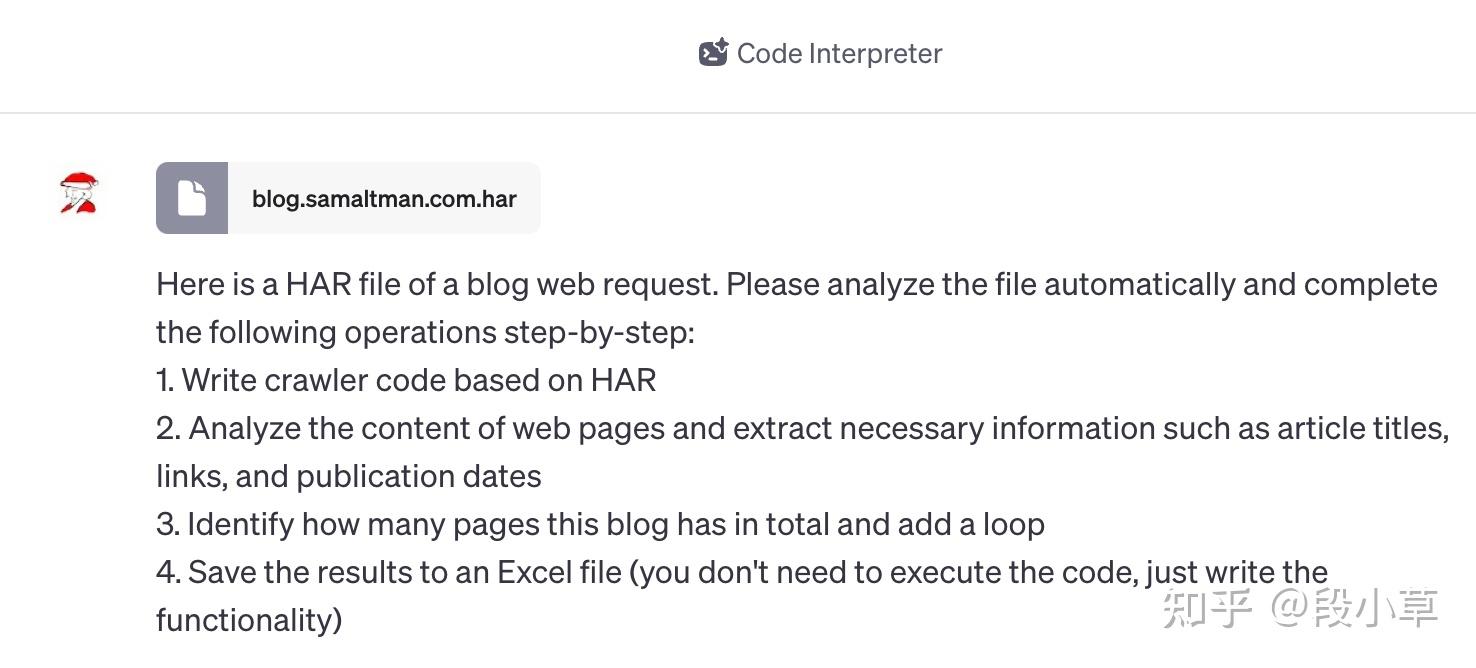
大家觉得哪个 Prompt 效果会更好呢…?
按道理应该是第二个,不过我实际比较下来,第一个效果其实挺不错。可能是因为任务比较简单,也可能是第二个任务步骤给的太详细反而限制了 ChatGPT 的发挥。
我把这两个对话都 share 出来供大家参考:
博客数据爬虫Crawl Blog Data我们以第一个为例,具体看一下 ChatGPT 的分析过程:
首先,它导入了json库来分析 HAR 文件,并从中定位了text/html类的请求作为网页内容。

注意,我给出指令时,只要求它提取「必要的有效信息」,这里的标题、链接、发布日期是它自己决定的:
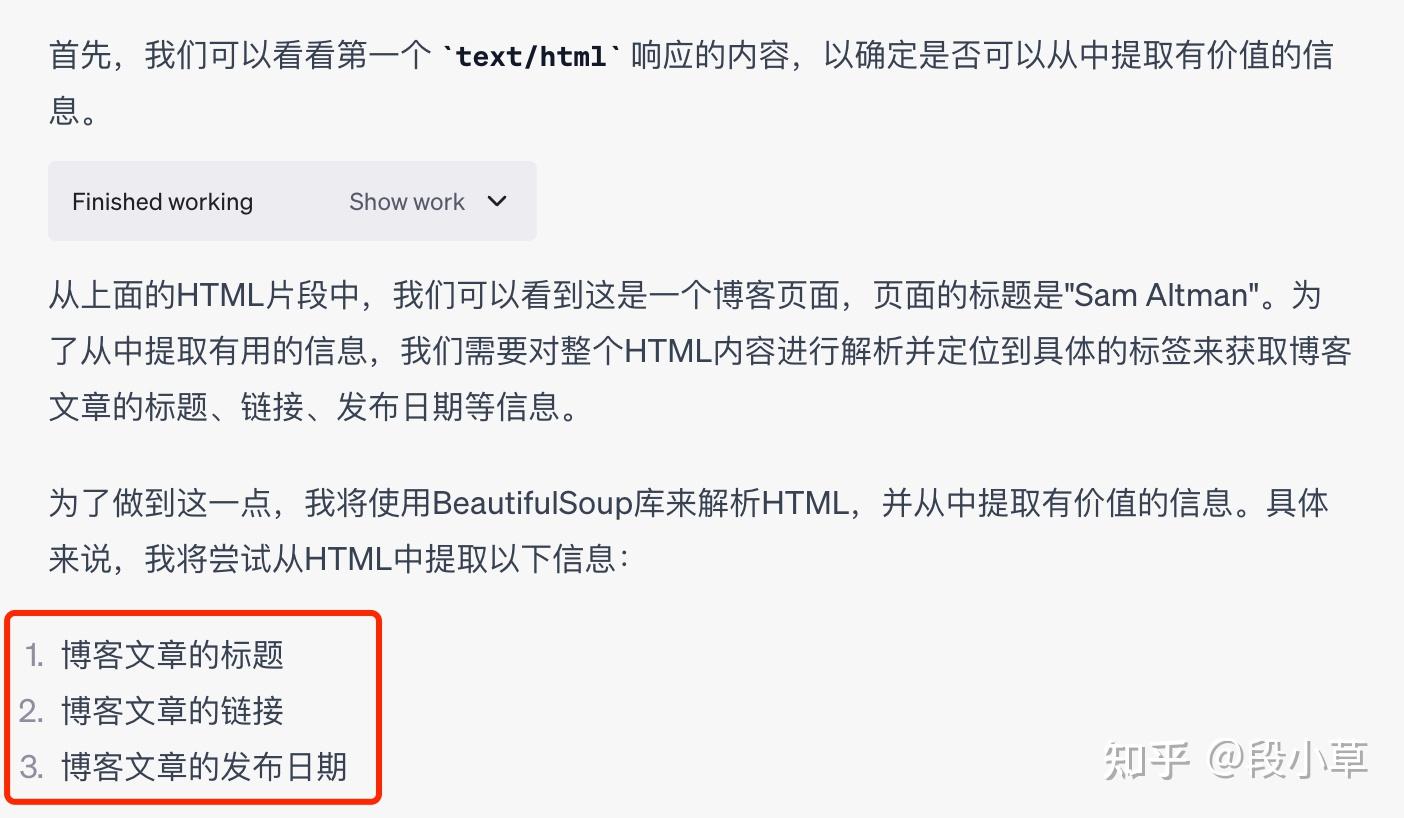
因为我们给的 HAR 只是博客的第一页,所以它提取出第一页的 10 条信息之后,再次询问是否需要做后续处理。此处记录的日期是时间戳形式,它也主动询问了是否需要转换日期格式或提取其他信息:

由于 ChatGPT 不能联网或者直接执行爬虫代码,所以后续我让它输出代码后自己在本地执行:
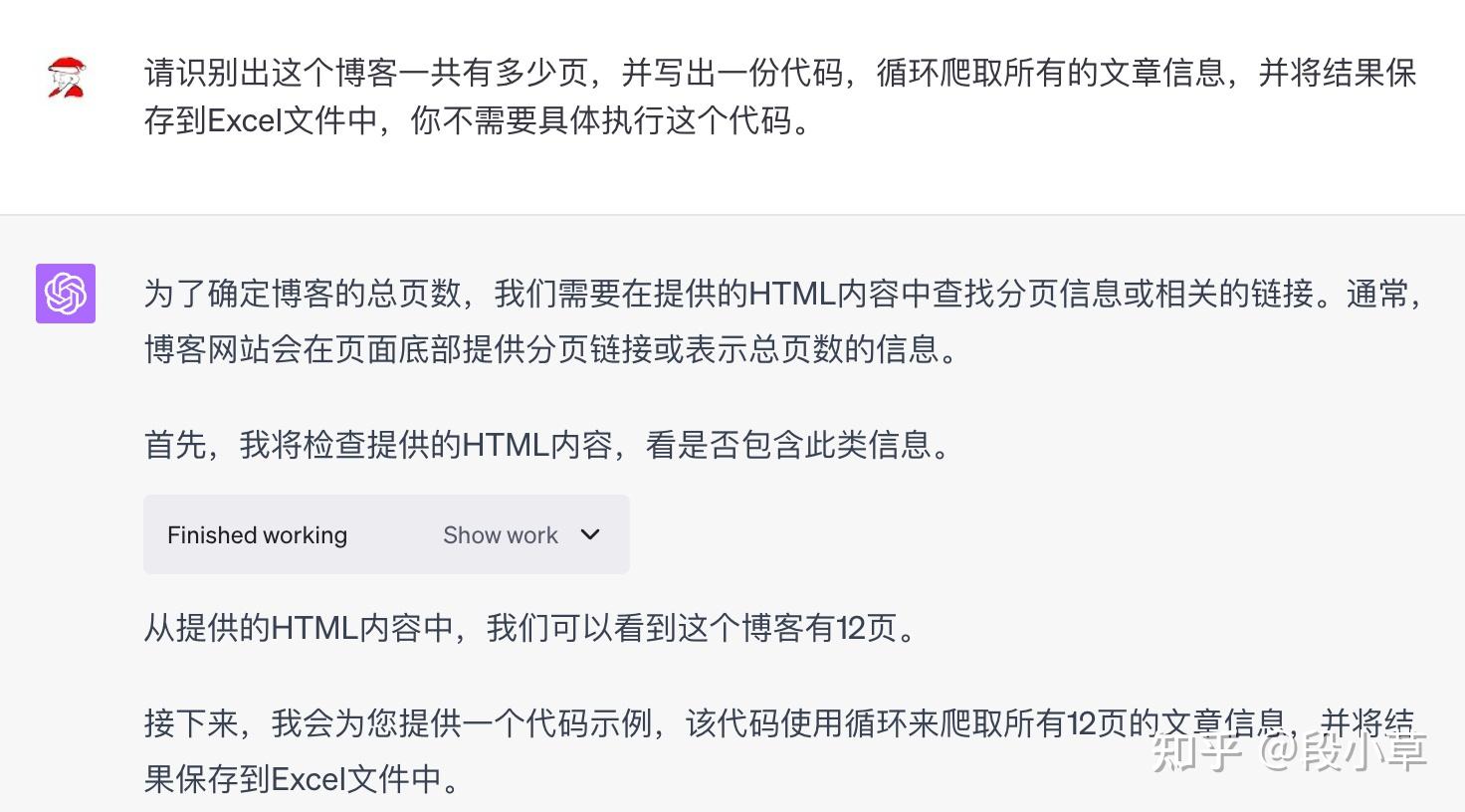
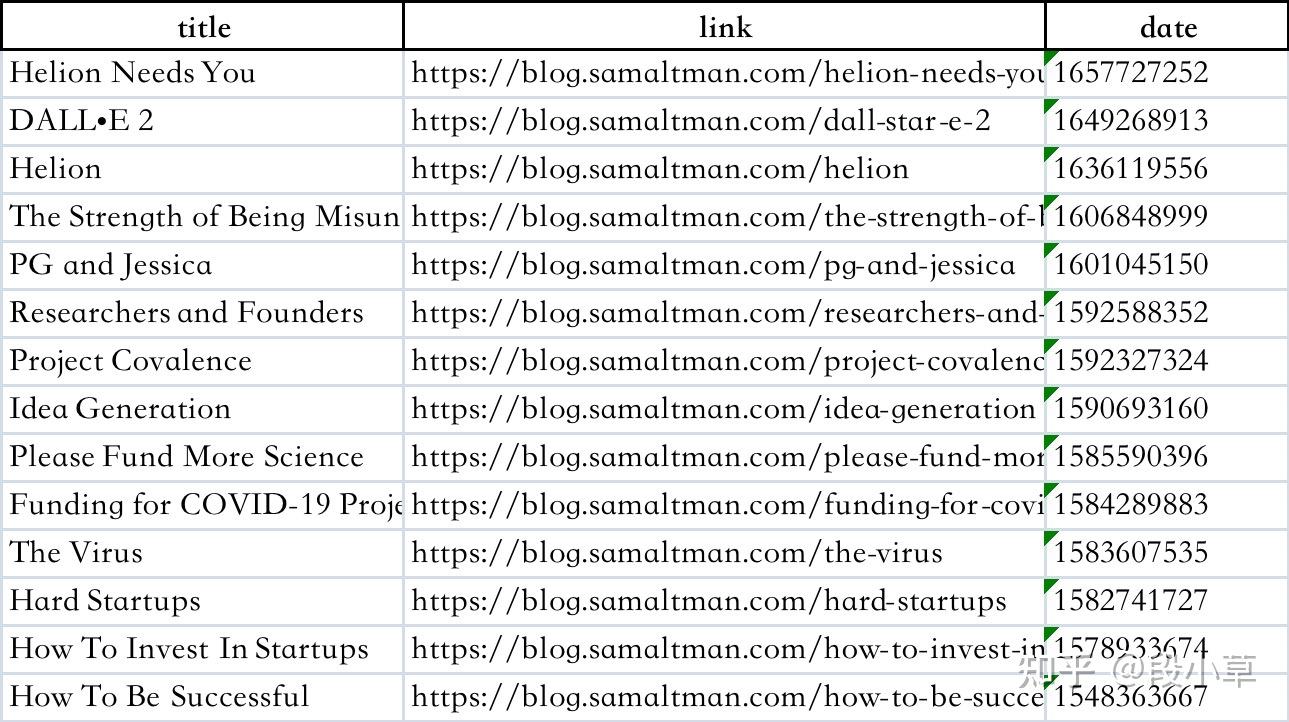
这是第一次的输出结果:
之后要求补充文章的点赞数据,并修改日期格式:
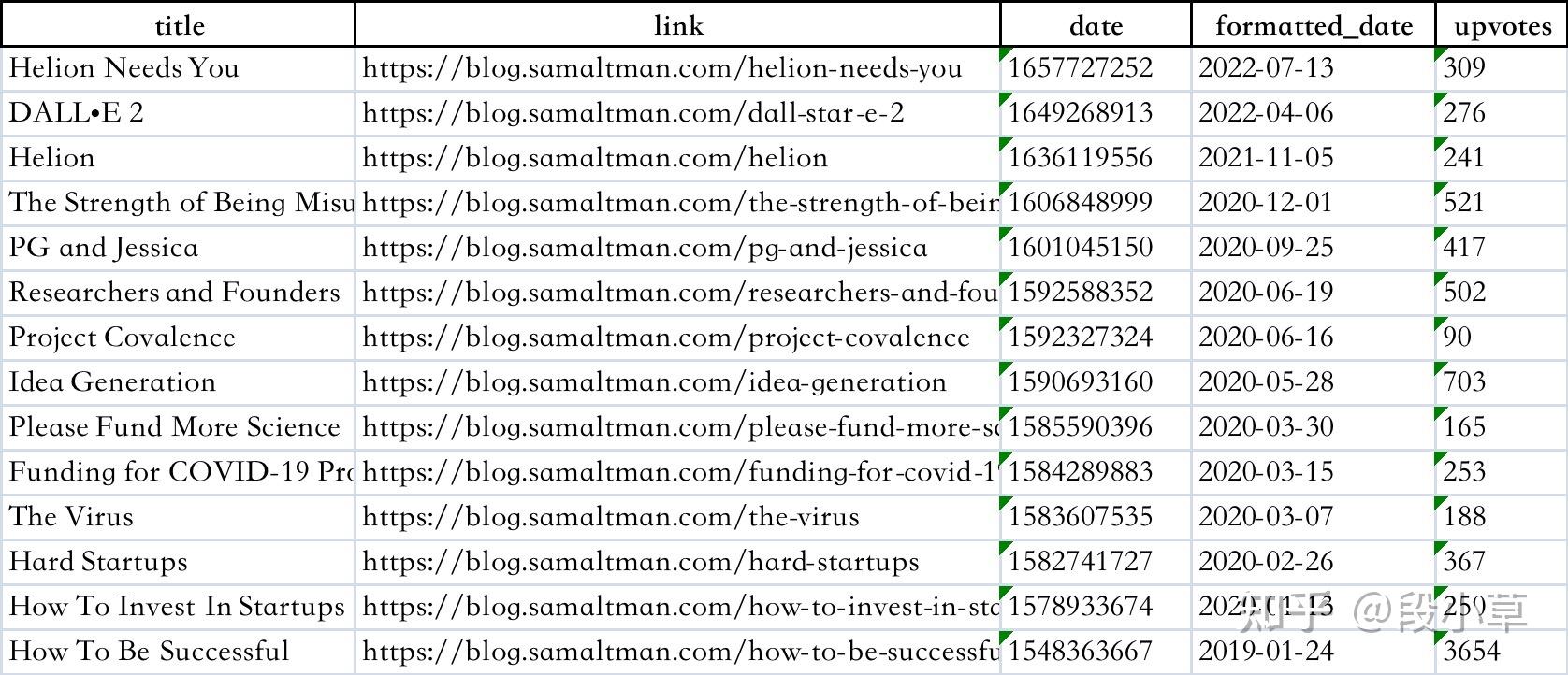
最终代码(可以直接运行,输出 Excel 文件):
import requests
from bs4 import BeautifulSoup
import pandas as pd
from datetime import datetime
def extract_blog_posts(html_content):
soup = BeautifulSoup(html_content, 'html.parser')
blog_posts = []
for article in soup.find_all('article', class_='post'):
title_tag = article.find('h2')
if title_tag:
title = title_tag.get_text(strip=True)
link = title_tag.find('a')['href'] if title_tag.find('a') else None
date_tag = article.find('span', class_='posthaven-formatted-date')
date = date_tag['data-unix-time'] if date_tag and date_tag.has_attr('data-unix-time') else None
formatted_date = datetime.utcfromtimestamp(int(date)).strftime('%Y-%m-%d') if date else None
# Extracting upvote data
upvote_tag = article.find('span', class_='posthaven-upvote-number')
upvotes = upvote_tag.get_text(strip=True) if upvote_tag else None
blog_posts.append({
"title": title,
"link": link,
"date": date,
"formatted_date": formatted_date,
"upvotes": upvotes
})
return blog_posts
BASE_URL = "https://blog.samaltman.com/?page="
all_posts = []
# Looping through all pages to extract blog posts
for page in range(1, 13): # As there are 12 pages
response = requests.get(BASE_URL + str(page))
if response.status_code == 200:
posts = extract_blog_posts(response.text)
all_posts.extend(posts)
# Saving the results to Excel
df = pd.DataFrame(all_posts)
df.to_excel("sam_altman_blog_posts_updated.xlsx", index=False)
(后续还做了数据分析,跟这一篇主题不太相关,以后再写吧)
last thing:风险提示
通过上文方式导出的 HAR 文件,可能会包含个人信息或 cookies,请自行判断是否适宜上传至 ChatGPT 平台,或在 ChatGPT 设置中手动关闭对话历史&数据训练选项,以免造成不必要的个人信息泄露和损失。
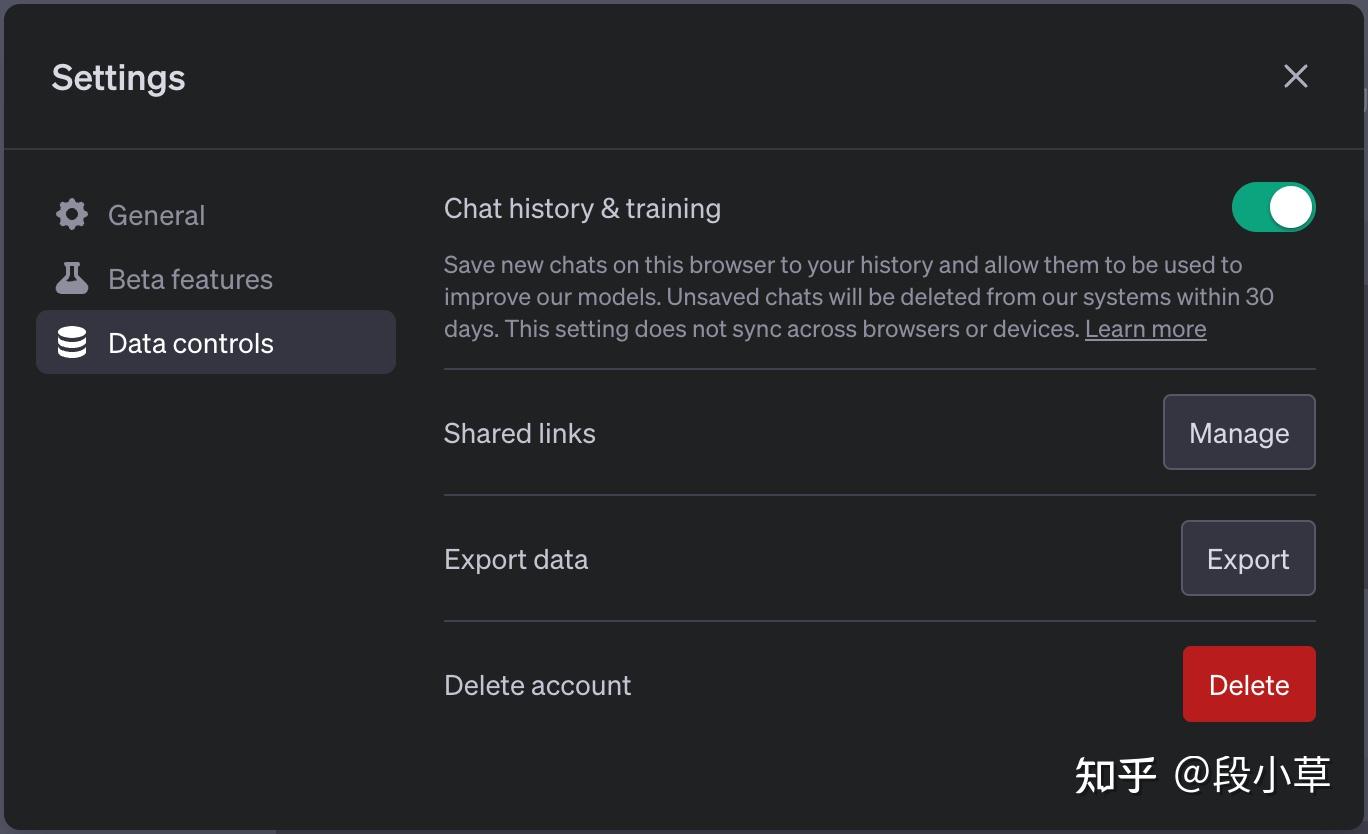
One more thing:逆向 JavaScript 代码
可能有人要说了,这爬虫代码也太低级了,不做 JavaScript 逆向也好意思说叫爬虫。
我只能说,我测试了两个带 sign 参数的页面,其中一个简单的 Code Interpreter 能自己分析 JS 并完成代码,另一个在引导下也能用 Python 模拟出相应的加密函数。不过涉及具体的网站,这里不方便继续展示。大家可以自己尝试一下,或者我之后找几个专门用于测试的页面吧。
(小细节,如果导出 HAR 文件的时候发现没有 JS 文件,可以清理缓存以后重新载入一遍)
总结,运用好 HAR 文件的特性和内容,可以完整地保存浏览器请求的过程,将这个文件提交给 Code Interpreter 进行自动化的分析,可以得到效果不错的 Python 爬虫代码,推荐大家实战测试一下。
以上。