深度学习的可解释性方向的研究是不是巨坑?
老问题了,但现在随着大模型和多模态的火热,这个方向绽放了新机会。我在另一个回答里开玩笑说,现在有LLM了,可以让模型自己开口说话了……如果说可解释性有什么终极解决方案,我觉得让模型自己解释就是终极解决方案。到了这个程度,可解释性就不仅仅是可解释性了,可解释性就代表智能本身,这个我在第三部分重点展开一下。
首先可解释性绝对不坑,我觉得这是一个非常有价值的方向,他没有KPI,没有东西可以卷,这就释放了无限的可能性。同时也是一个很重要的问题,毕竟谁不想多理解一点神经网络呢?
我为什么对可解释性这么看重呢,因为我是搞自动驾驶的。汽车行业一直追求安全性,和神经网络是天然的敌人,这也是深度学习最为人诟病的地方,谁会愿意把自己的生命托付给一个automagic的黑盒呢?在对安全要求很高的应用领域,可解释性是非常重要的,咱不说每一次推理都必须可靠,但至少出问题了要能给模型debug吧?
我的很大一部分工作其实就是给模型debug,想办法解释为什么模型出了问题,以及如何解决这个问题。他不像写程序,你单步调试总能定位到问题,要搞清楚神经网络在干嘛,需要用上望闻问切各种手段。可以这么说,给神经网络debug就是在尝试解释他。你想想一个程序员每天大部分时间都在debug,那同理,一个深度学习工程师也要花大量的时间给模型debug,所以这个方向怎么会是坑呢 。。。
我就谈谈我比较了解的三个方向,都不是特硬核的那种。一是解释一个训练好的神经网络,搞清楚他的运作机制;二是让神经网络除了输出任务需要的结果之外额外输出辅助的解释性结果,比如不确定度,中间结果等等;三是用自然语言解释,甚至一边解释一边推理,解释的过程就是推理的过程,这是终极目标。
一、 解释一个训练好的模型
给模型debug,就日常工作而言,这是最有用的。举两个例子,我遇到过的两篇很有用的论文是这两篇:
一篇论文是解释单目深度模型是怎么预测深度的。大家都知道,只通过一张图从物理上说是不能重建图里的三维信息的,但人眼可以,那么神经网络也可以,也就是单目深度预测的任务。这就很魔法了,模型凭什么去感知深度信息呢?这篇文章就是研究这个问题的:
How do neural networks see depth in single images?
TLDR,作者做了大量的实验发现了大量单目深度模型的思维模式和缺陷。比如对深度的感知依赖于路面,对物体的感知依赖于物体在路面上的投影:
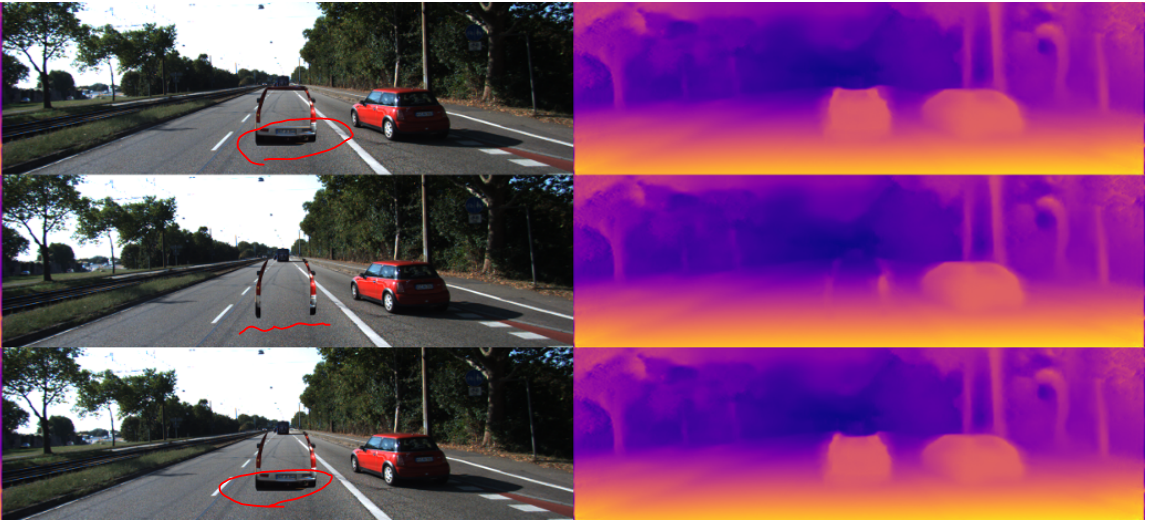
其实实验不难做,道理不难懂,但总得有人发掘。这文章,论难度,比很多卷KPI的文章低太多了,但也是ICCV的文章啊,引用也接近150了,不错了…
另一篇文章是通过实验告诉我们语义分割对context的依赖性。在同一张图里面,原本模型能够准确的分割右侧人行道,作者把左侧路边停的车移除之后,右侧的人行道就分割得乱七八糟的了???
这个实验逻辑有点类似于常用的注意力热力图,就是测量各个像素对最终输出结果的重要性,但他是在object level操作的,更容易被人类理解。毕竟面对一个热力图,你其实是手足无措的,但如果告诉你左侧路边的车辆对右边人行道的分割至关重要,那就make sense了:
Not Using the Car to See the Sidewalk: Quantifying and Controlling the Effects of Context in Classification and Segmentation这论文,知道的人也不多,也没什么名气,引用也没过100,但对更好的理解语义分割还是很有用的。
二、 让模型输出更多的辅助结果
模型只输出一个结果,那就没有任何解释性了,所以我们可以加入各种各样的辅助任务增强可解释性。很多类似的工作其实都是这个方向的,但没有被归类到模型可解释这一类里面来。
比如Alex Kendall研究的不确定度学习和多任务学习。通过学习不确定度,模型会给使用者多提供一个不确定度信息,这个是非常有用的。有时候模型输出的不确定度很高,这个结果就可以直接当垃圾处理了。
又比如多任务学习,你需要学习某个终极任务A,但为了达到A,你把A任务拆解成BCDEF,然后给每个子任务都安排一个模型去学,然后把BCDEF组合在一起完成A任务。今年CVPR的最佳论文UniAD也可以归为此类。这样做的话终极任务A的可解释性就大大增加了,很多比较大的任务都可以依次办理,不过一般也不把这些工作归类为模型可解释性的工作。
其实还有一类比较硬核的是类似于马毅教授White-Box Transformers和ReduNet,以及Hinton 的Forward-Forward的文章。就是让神经网络的每一步都具有可解释的数学或物理或仿生学意义。步步可解释,则总体可解释。
三、 基于自然语言的可解释性
我们追求模型可解释,为什么?因为我们不知道模型在干嘛,我们无法信任一个模型。所以搞出来了很多注意力图,不确定度,高维流形之类的工具让模型变得可以理解。但总是隔了一层,有种隔靴搔痒的感觉,因为这些解释的工具不是我们用来沟通的工具——语言。
所以最好是能让模型自己开口说话,让他自己解释为什么会输出这样的结果。这是一个比较人类中心主义的出发点:我不想按照你的思路去理解你,我只想让你用我的语言给我解释。
但模型如果要用语言来解释自己,这就暗含了一个前提:模型的推理过程能够用语言和逻辑来表达。所以语言就不仅仅是一个用来沟通的中介了,同时也意味着我们在强迫模型用人类的思维推理。我们之所以相信别人,是因为我们相信别人会用人类的理性解决问题。而人类理性的载体是什么?——语言。
也就是说,模型用语言解释自己的输出结果=模型用符合人类理性的思维推理=真正的人类智能。
所以我说模型的语言可解释性和实现智能本质上是一样的,否则如果你不能用人类的理性进行推理,那也就无法用语言解释就只能借助其他的工具。
用自然语言解释现有模型
一个方法是用自然语言解释一个和自然语言无关的模型,比如今年发表的ADAPT,一个自动驾驶模型,两个分支,一个输出车辆控制信号,另一个输出解释语句:
[2302.00673] ADAPT: Action-aware Driving Caption Transformer (arxiv.org)
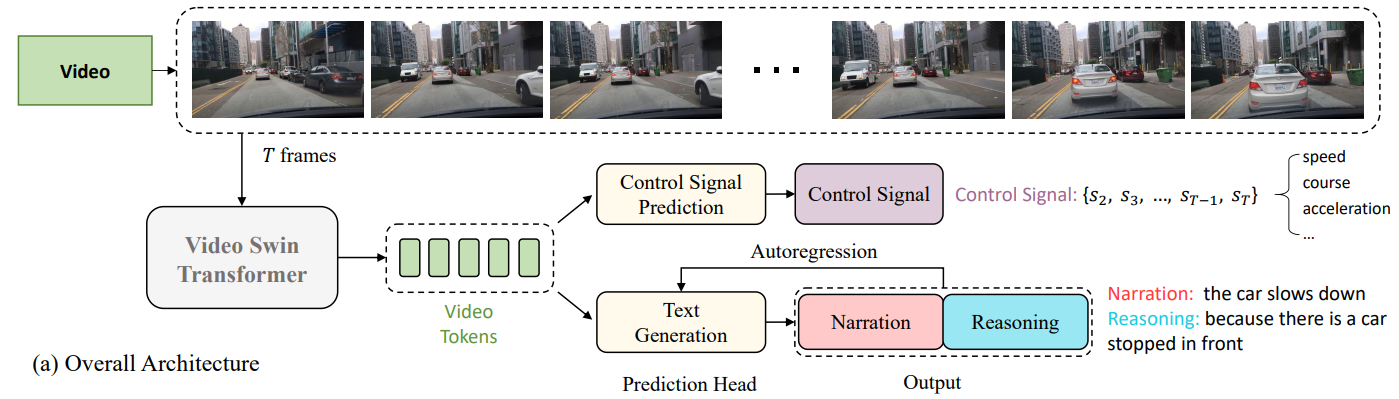
虽然文章称两个任务一起训练,有助于他们之间的aligment,但是大家都知道,控制信号的输出终究还是没有和语言分支很好的对齐。。。所以这个解释分支用来给乘客看看,作为一个增加信任度的输出还可以,但并没有实质性的解释力,因为这模型还是在用他的思路思考,仍然不是人类的理性,等于是强迫一个分支去解释另一个。
将自然语言融入到推理过程
所以一定要在模型进行推理时,把语言塞进去,强迫模型利用语义信息进行推理。这就涉及到视觉特征和语言特征的融合。一种做法是类似于SAM的:
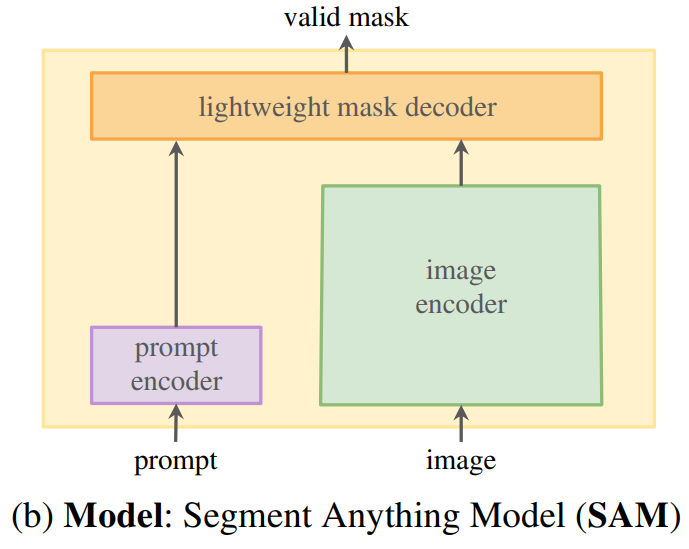
SAM的目的不是可解释性,仅仅是希望从图像中query出和prompt相关的mask,其实就是算了一个相关性:
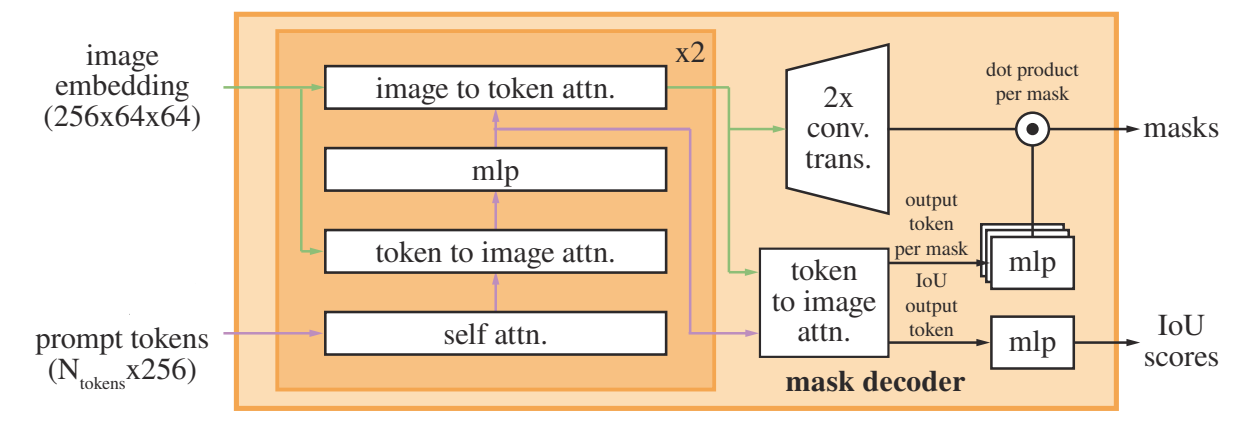
这个月还有一个工作叫LISA:
LISA: REASONING SEGMENTATION VIA LARGE LANGUAGE MODEL
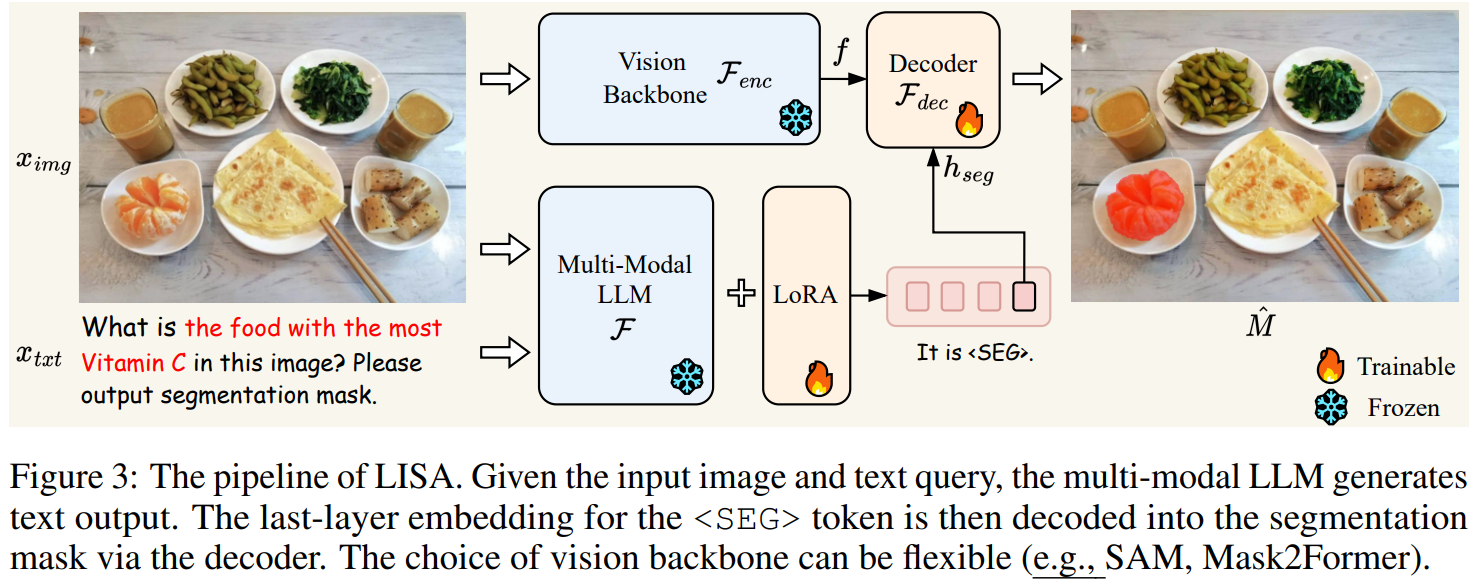
图里面标记了雪花的是冻结部分,直接拿来用的,带一团火的是可训练部分,图中的Decoder和SAM一样,另外还给多模态大模型加了个LoRA进行微调。这个模型和SAM是非常类似的,唯一的区别是用上了大模型,增强了推理能力。文章也展示了一些解释能力,其实和我们想要的解释能力完全不是一回事,仍然没有和视觉模型紧密地联系起来。
比如他给一幅拳击比赛的图片进行分割,要求分割出失败者:

然后他输出了一大段解释,比如被击败的人是被胜利的人控制住了,位于下方等等等等。这当然也可以算解释吧,但我也很关心这个问题:你为什么觉得被分割出来的物体是个人?
让模型用自然语言思考
也就是说,为了进行解释,我们需要让模型用自然语言“思考”。那不如干脆让视觉模型的特征带上语义,不难想到,可以直接上CLIP。但CLIP是把图片和文字进行对应,也是在最后进行alignment,而发生在Image Encoder中间的事情,CLIP是无法控制的:
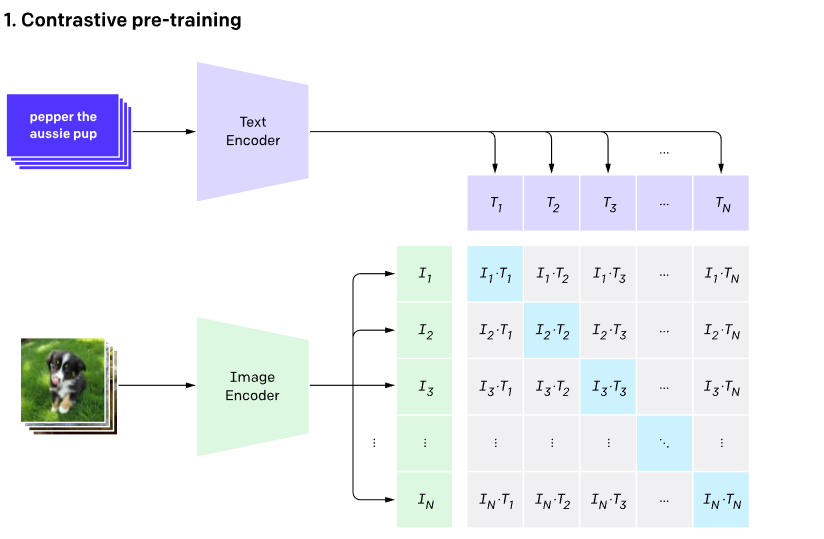
所以要把CLIP精细化,最好是让每一个像素都带上语义。X-VLM做的就是这个事情,使用和CLIP类似的视觉—语言对比学习把视觉特征和语义特征的对齐细化到了patch级别:
Multi-Grained Vision Language Pre-Training: Aligning Texts with Visual Concepts
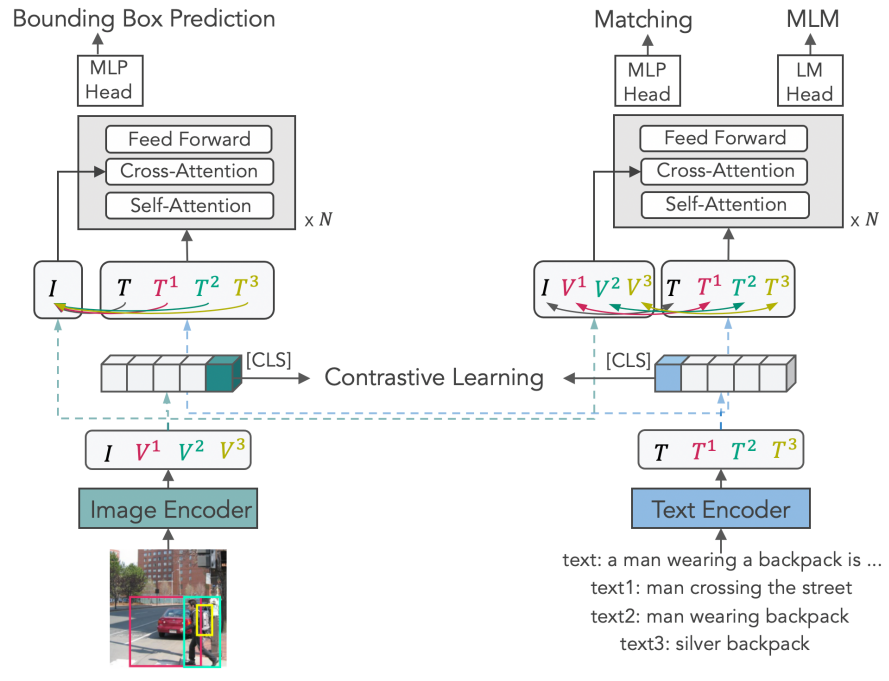
图中的Image Encoder是一个ViT,出来的视觉特征是经过编码的一个个的patch,每一个patch去和Text Encoder出来的语言特征进行匹配和对比学习。和CLIP原理一样,不过把粒度降低到了patch的级别。这也就意味着,ViT输出的每一个patch,都有了语义。
还有更夸张的,直接把语言特征硬塞到视觉模型的中间特征里:
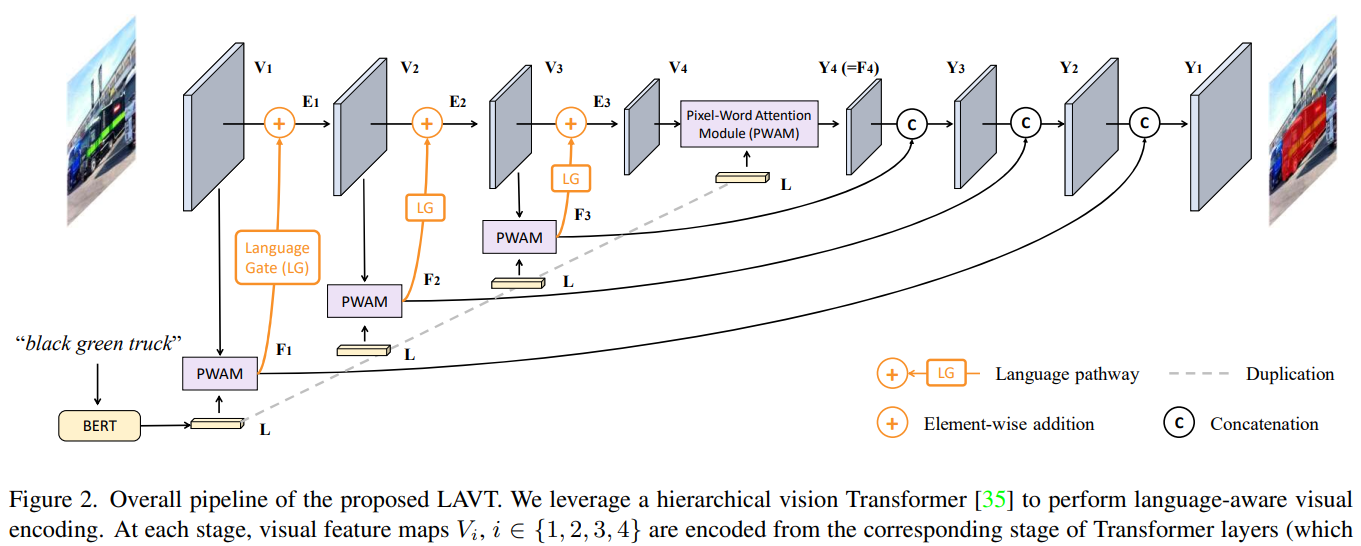
当然这个硬塞的作用,更多的是提高视觉特征的language awareness。或者从语言的角度考虑,我们通过输入语句,在不同的视觉层级上去“收集”和语句相关的视觉特征。
总之,让视觉特征和语义对齐,是视觉语言模型必须解决的问题。比如Flamingo中的Perceiver Resampler,BLIP-2中的Q-Former,都是同理。而且这些最新的视觉语言模型,不仅是将视觉特征和语言特征进行对齐,同时还进行了融合,
那么如果一个视觉模型输出的视觉特征图,每一个patch,以至于每一个像素都带有语义,都是meaningful的,你想想看这意味着什么?这意味着:

你可以按照这个思路考虑让他识别一个人,并解释为什么他觉得这是一个人。最理想的情况是他告诉我他看到的物体有眼睛,嘴巴,耳朵 etc。。。所以这是个人。不知道哪里可以跑Flamingo的demo,我是真的想试试 。。。
但这里存在一个问题是,我们非要让一个视觉模型去和人类的语言对齐,会不会牺牲了视觉模型的性能呢?可喜的是,人类的语言特征表达能力足够丰富,据某大佬称,某视觉语言大模型在很多视觉任务上达到了sota。所以应该是问题不大的,不过对于三维感知之类不可描述的任务,可能还有待观察,我估计是不太行的。
完全用自然语言思考
凡事都有人走极端,假设某个任务的输入可以很容易的转换成语言描述,那是不是啥模型都不需要,直接把输入转换成语言后,用LLM解决问题就完事了?最近有篇论文就这么干的。。。真的脑洞太大了,而且仔细想想,还真的满可行的。他们用自然语言描述行驶环境,然后让ChatGPT输出控制指令???
Drive Like a Human: Rethinking Autonomous Driving with Large Language Models
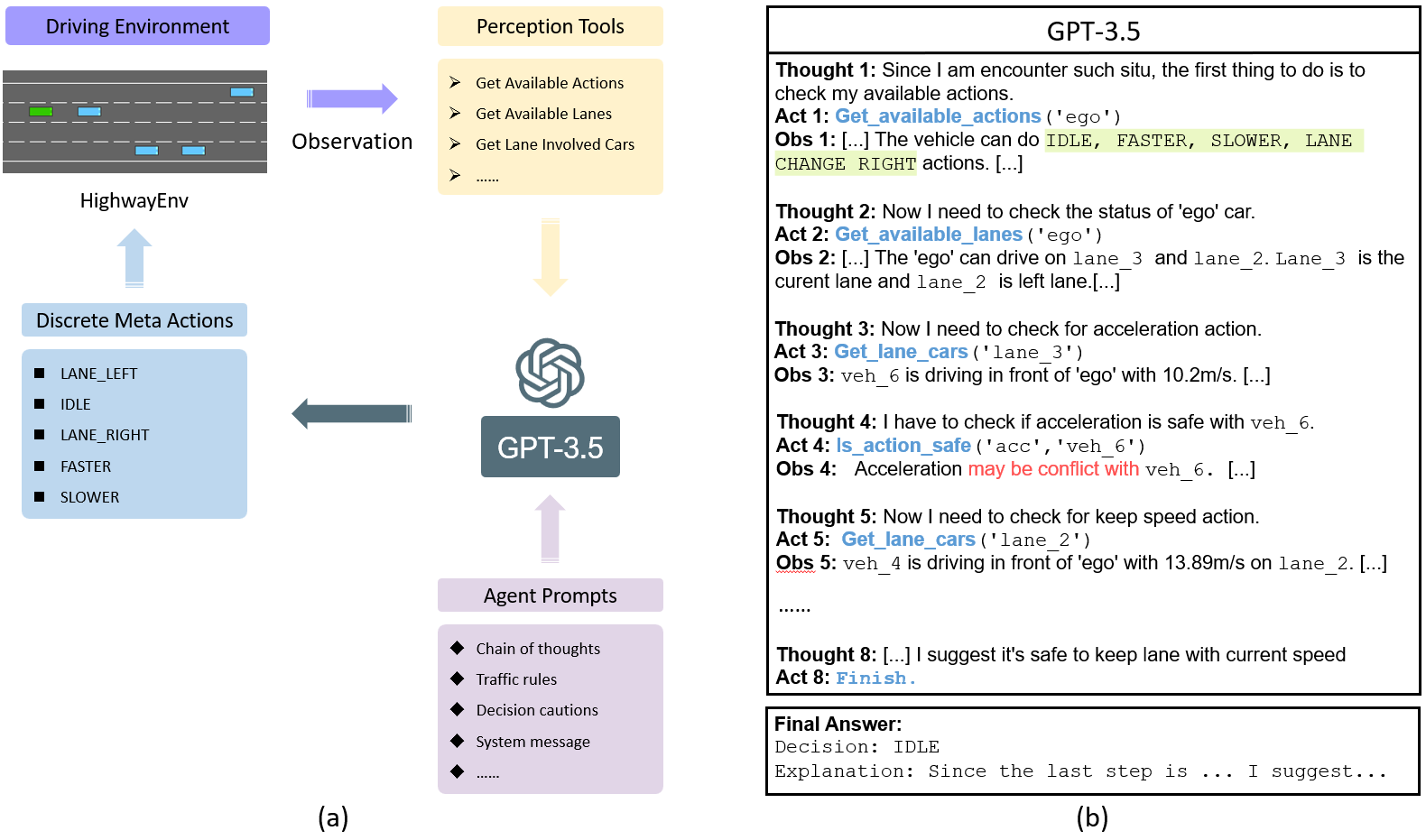
这应该算是完全可解释的policy network了吧???
总之,我觉得语言模型的加入为模型的可解释性打开了一扇新的门,大家可以留意一下。当然,也是一个新的巨坑,感觉挺耗算力的就是……