为什么Rust 标准库的 TreeMap 采用 B 树实现,而不是常用的红黑树?
其实这个答案在rust的docs网站上已经有个清晰的阐述,我接下来只是把这些阐述以自己的语言搬运过来,链接在最尾。
简单来说,BST确实是理论上内存数据结构的最优解,但是有个前提:内存是真的均质随机访问内存。这里给出一个定义,均质随机访问内存即主存拥有在任意上下文场景下,访问任意地址,都有着非常相似的性能。但是很不幸,现在的内存并不是这样子的。
在计算机当中,由于cache的存在,访问临近位置的内存在平均意义下会产生非常巨大的性能提升,而BST的特性导致临近的元素并不是在内存中存放在一起的,从而在实践当中性能非常糟糕。而B-Tree在大部分场景下,可以让一些临近元素在内存中存放在一起,从而在大部分情况下,实践中得到比BST更好的性能。
2022-03-25:
有朋友提到了BTree的实现也不是完全连续,这里添加一条基于比较的字典类型的连续性对比:
self-balancing BST(几乎完全不连续) < BTree(部分连续) < LSMT (几乎全连续,偶尔不连续)
2022-08-23:
有朋友在评论中说为什么不用B+Tree而是B-Tree。说真的,这个问题对我来说一上手还真有点棘手,原因是我之前的答案讨论都是吧B-Tree这个词当作B族树这个概念来用的,并没有展开说到底是B+Tree还是传统B-Tree。我也并不知道Rust里面是不是真的用普通B-Tree而不是B+Tree……
于是我去读了下Rust的标准库代码,确认了Rust使用了标准的B-Tree,而并没有把index单独建一层形成B+Tree。这里摆一张证据在这里,Rust search node会有Found状态,而Found状态会短路直接返回,这就是B-Tree和B+Tree的区别,B+Tree是不会短路的。
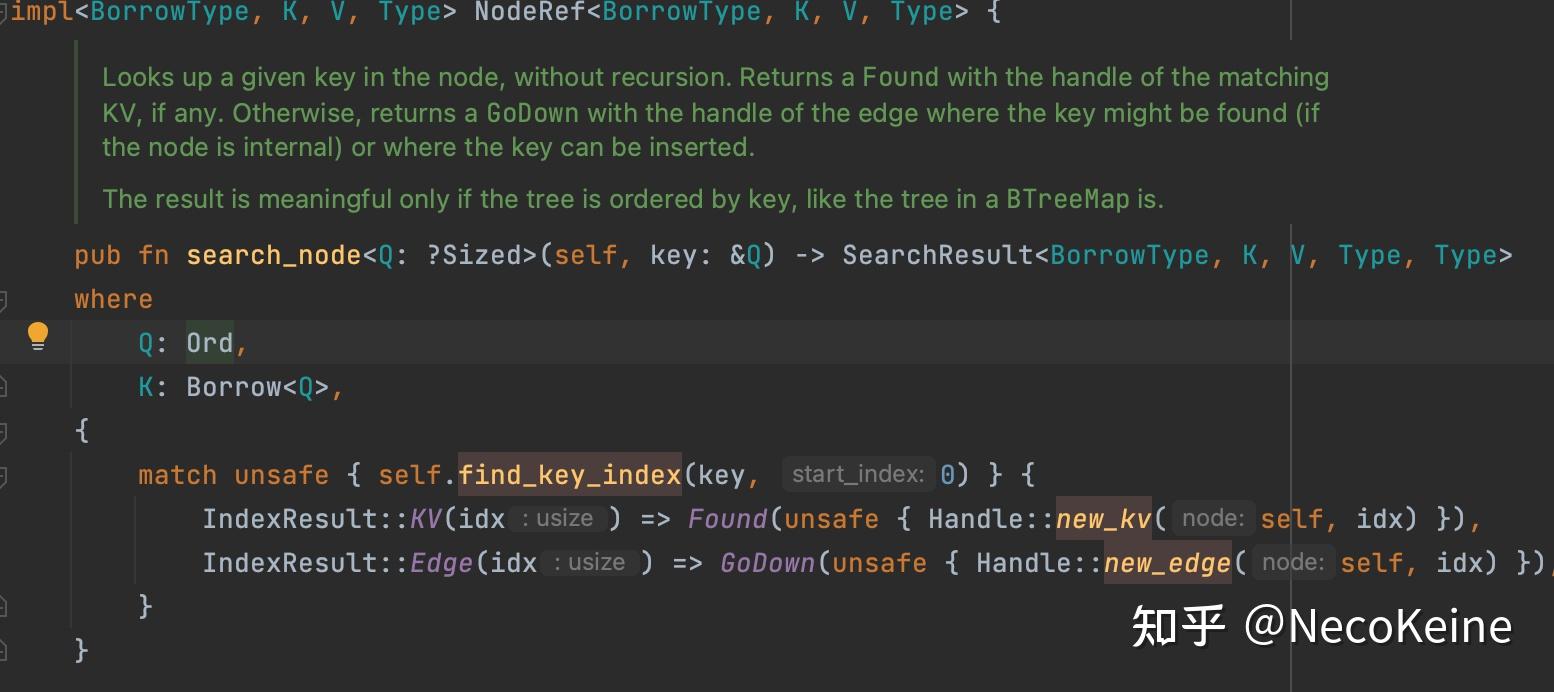
接下来我们来分析下B-Tree相对于B+Tree的优劣势:
- 优势:省内存,不需要多做一层索引。
- 劣势:Iter略慢,next() 最差会出现log n的复杂度,B+Tree可以稳定O(1)。
- 劣势:可以区分index和数据,把index做的很小,放进更快但是更小的存储中。
首先Rust的BTreeMap是全放在内存里的,第三条基本上就没啥用,第二条的性能提升微乎其微,但是第一条的省内存可是实实在在的,所以B+Tree在这个使用场景下GG。
再给大家添加一个B+Tree很适合的使用场景来进一步学习下B+Tree,一个典型应用是硬盘KV数据库,开启数据库的时候根据硬盘中保存的叶子结点们在内存中构造出来B+Tree的index部分,这样子的硬盘KV的读写一个key一般只需要hit一次硬盘就可以完成,当然触发平衡时候会是多次,但是相比于纯硬盘BTree的log n次硬盘操作(index大 内存塞不下)而言,优势非常明显的。