公司一个5年JAVA,这业务写那么多IF-ELSE是什么水平?
坦白说,这段代码不是严格意义上的“无可指摘”。但是在兼顾工程效率和清晰性的平衡上,已经是一个很合适的选择了。要是我碰上同伴能写出质量这么高的代码,做梦都得笑醒。
好吧,但在这里简单地夸赞“这已经足够好了”没有太大意义。这里就以我拙陋的浅见简单挑挑刺。

首先一看可以看到这段代码大概率没有使用格式化工具,所以可以发现第90行的String.format中将逗号放在了行首,而第106行的String.format却将逗号放在了行尾。并且,第92行同时在行首和行尾出现了逗号,看起来不够统一。
这里简单用格式化工具整理一下,并加上一些适当的空行。

然后,我们发现代码中存在一些比较冗长的常量表示。就我个人来说,是不太喜欢将所有常量简单地放到一个全局的的Constants里的,我可能会考虑直接将这里的Operation枚举直接放到Model里。但这只是个人风格问题,在这里为了尽量少改动外层的代码,就只是简单地使用静态导入简化代码。

不过,如果这段代码处于某个较大的文件,使用静态导入常常存在污染命名空间的风险,因此在实际中是否真的值得为了简洁性而使用静态导入需要一些权衡。
另外,对于Java之外的绝大多数编程语言,由于别名的存在,可以通过直接在这里为Constants.Excel.Model.Operation起别名达到类似的效果而不污染命名空间,如在TypeScript中我们可以简单地编写const Operation = Constants.Excel.Model.Operation。
然后,发现开头的一些条件判断式稍微有些复杂,不容易一眼看出目的。因此,这里使用helper function或干脆直接加个中间变量的方法,使它们读起来稍微轻松点,并顺带着加点注释。(说实话,这段代码已经够易读了,这里只是为了吹毛求疵)


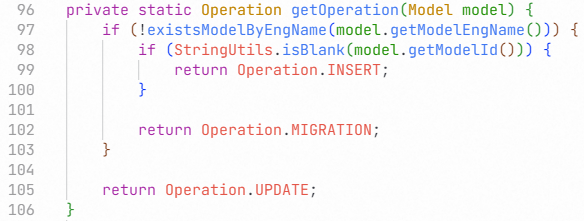
可以看到,这里实际上引入了一点效率问题。在最外层if的else分支中,本来只需要从数据库中查找一次模型,但这里由于引入了existsModelByEngName,因此其实查找了两次数据库。如果这本来就是一段很少使用的功能,并且经测试发现查询速度足够快,那么这样写是没有问题的。但如果这段对性能有较高要求,则可能产生问题。
不过,在很多稍复杂一些的系统中, existsModelById和existsModelByEngName的实现不应像这里演示的这么简单。例如,可以使用MySQL的EXISTS关键字,利用数据库索引以较快的速度获知数据库中是否存在对应实体,如果在大部分情况下数据库中都不存在该实体,这么写或许反而比查询对应实体并判断是否为null更快。在更复杂一点的情况中,或许已经通过Redis等缓存技术将部分实体缓存到了内存中,此时existsModelByEngName的效率可能非常高,由此带来的时间损耗甚至完全可以忽略不计。
然后,我们意识到这段代码的最大问题就是存在本可以消除的状态。为了减少缩进层次,我们常见的方案是使用函数抽离某段逻辑并使用提前return。但是在这里,由于model上存在的这个optionMark属性,我们没办法使用类似的手段解决问题。
可以看到,这段代码唯一的副作用就是改变model的optionMark属性。我们完全可以将这段逻辑包装成一个函数,返回Operation类型的标记。


看起来更干净了一些。但是我们现在也意识到一点:这个函数似乎太长了,尝试做了太多工作。目前来说,我们至少意识到可以把两处校验逻辑单独抽离出来。


这样清爽多了。但是,似乎这还是不够。这个函数毕竟把校验和标记两个功能放在了一起,一次尝试完成两件事。我们更应该遵循关注点分离原则,在一个函数中只做尽可能少的事。


同样的,这样的修改也引入了一些潜在的效率上的问题,可能引入了更多的数据库访问,需要具体权衡利弊,或是为existsModelById和existsModelByEngName提供更好更有效率的实现。
但是,我们可以看到,现在整个逻辑变得无比清晰:
- 首先校验输入。若数据库中已存在对应ID的Model,且英文名不一致,则认为尝试更新该Model的英文名,这不被允许,抛出异常;同理,若数据库中已存在对应英文名的Model,且ID不为空,则认为尝试更新该Model的ID,也抛出异常。
- 如果数据库中不存在对应英文名的Model,且ID为空,插入Model。
- 如果数据库中不存在对应英文名的Model,但ID不为空,则执行迁移。
- 如果数据库中已存在对应英文名的Model,更新该Model。
说实话,我们目前的实现比起最初版本长了可能有近一倍,并且效率上也略有下降(不过,正如上面所说,如果两个exists函数具有较好的实现,不会降低多少效率,甚至反而有可能使程序运行得更快)。但现在我们将多个关注点分离开,减少了一些嵌套层次,使代码更加易懂。并且,在重构过程中创建的这些函数可以更好地被组合,甚至方便在其他场景中复用。
不过,我其实不敢保证这些即兴的重构一定没有BUG。事实上,如果真要进行这样的重构,我会在每执行一步重构后都运行一遍单元测试,确保重构没有引入新的BUG,否则我断然是没有充足的信心就这么一连串地重构下去的。这也是所谓的“小步重构”原则。
很多魔怔Java工程师喜欢滥用设计模式把这样代码中的if给“消灭”掉,他们最引以为傲的事情是“我今天又带领团队消灭了3000个if”这种蠢事。但是,上面我们重构后的代码一个if都没有“消灭”掉(甚至引入了更多的if),却仍旧很好地提高了代码的可读性。我个人的观点是,对于这样细粒度的业务逻辑,强行套上设计模式完全是吃饱了撑的,简单地应用几个原则进行重构一样效果很好。
不过也正如很多答主说的,Java冗长的语法导致这个本来简单到根本不需要重构的逻辑变得看起来让人有重构的欲望……
而且说实话,这么重构还有另一个问题,就是导致类里出现了一堆private方法,污染比较严重。假如这段代码在一个特别大的类,出现一个名叫getOperation的静态private方法看起来一定很怪,或许还要考虑把这段逻辑单独拆分到一个类里去,比如什么ModelUpdateInputProcessor。在一个支持嵌套定义函数的编程语言中就要好得多,可以直接用嵌套作用域把函数隔离开——当然,其实上面的几个方法都改成lambda也不是不行,这样就可以放在一个作用域里了,就是在Java中不太常规。
有答主以Scala演示了一下在Pattern Matching下这段逻辑是多么好处理,我姑且也开启--enable-preview用Java最新的Pattern Matching也尝试着写一下……
警告,下面这段代码可能引起生理性不适,请谨慎阅读。

这真是我这辈子写过最恶心的Pattern Matching了。如果有人对Java这个最新的Pattern Matching比较熟,希望能在评论区告诉我一下这代码哪里有问题,并且还能做些啥来简化这么一坨不可名状之物……