在现阶段的神经科学和脑科学的研究中,有没有人脑结合 AI(人工智能)的方向?
神经科学和人工智能的最近几年的发展都十分迅猛,而这两个领域的发展其实也是相辅相成的。
信息表征
一个重要的方向是研究:人类大脑和AI模型对于信息的表征是否相似?
信息指的可以是视觉,听觉,语言等等。视觉领域的比较与探索是最早开始的。
我首先想介绍一个大牛,MIT MCGovern研究所的James Dicarlo。他们对大脑与AI视觉表征这个领域有很多重要的工作。
The DiCarlo Lab at MIT
监督学习模型
2014年,人工智能热潮刚刚开始不久,他们就在PNAS发表了一篇重要工作[1]。
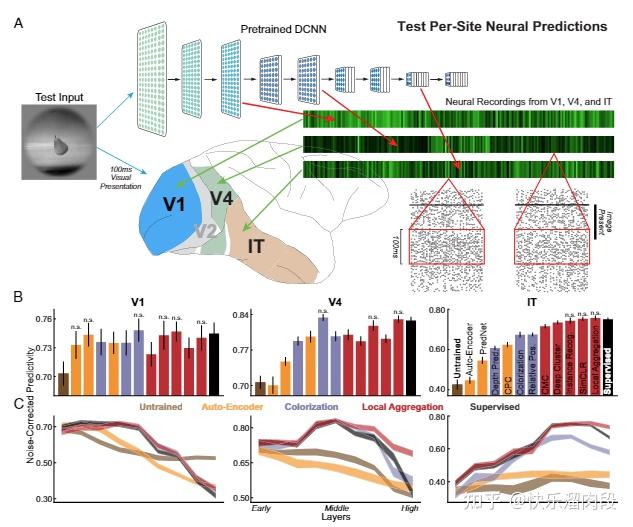
他们训练猴子做图片分类任务,记录V4和IT脑区(两个高级的视觉脑区,IT表征的信息比V4更加抽象)的神经元反应。同样的图片也被输入CNN(他们自己设计了一个叫HMO的CNN),获得CNN对图片的表征。
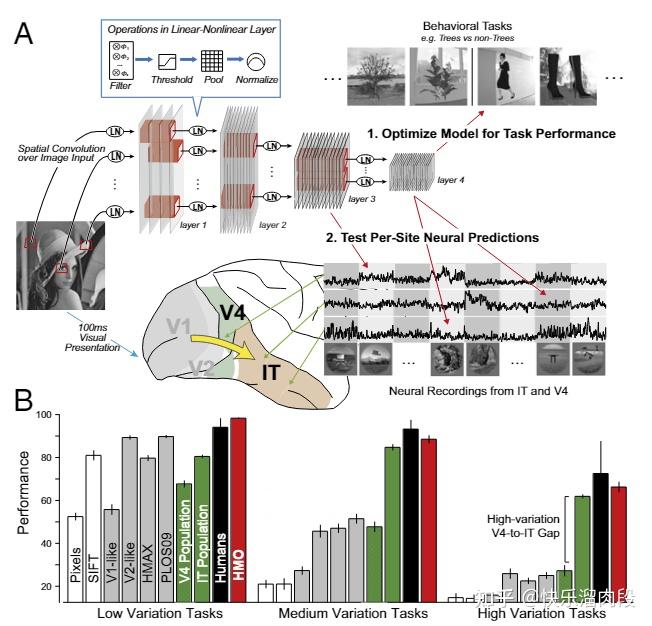
第一个实验是用V4,IT神经元数据,以及CNN表征训练SVM,测试分类性能。
他们控制任务图片集的差异程度,测试了三种不同难度的任务。结果表明,在各种难度任务下,CNN都可以取得与IT相似的分类性能。甚至在更加困难的分类任务(Hight Variation Tasks)中,CNN表征的分类性能要显著超过V4神经元表征。
这说明CNN对图片的表征可能与IT存在很强的相似性
进一步的实验是,用直接用CNN的表征+线性回归去预测了V4/IT神经元的活动。
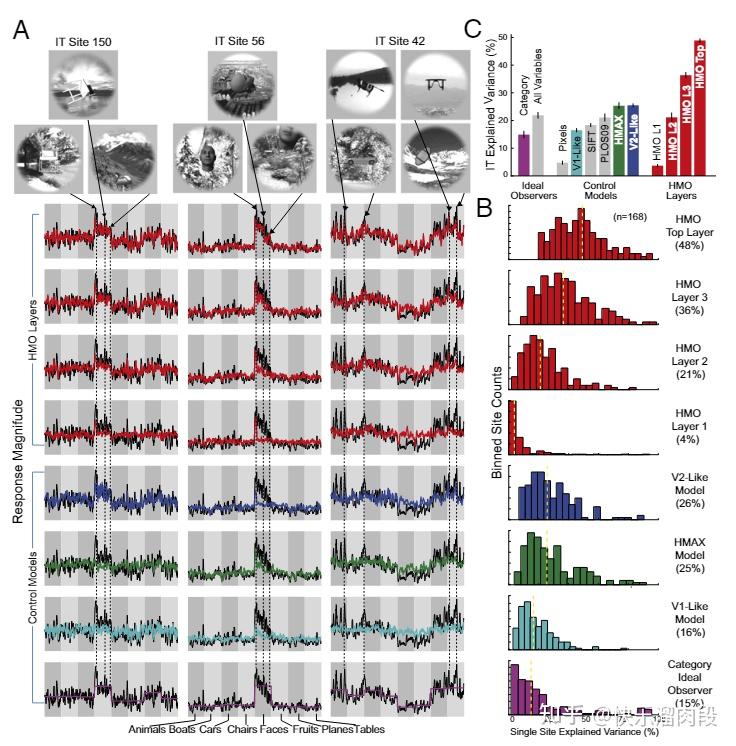
预测结果表明,CNN的top hidden layer可以很好的预测出IT的活动,middle hidden layer则可以很好的预测出V4的神经活动。
这说明,CNN与大脑视觉系统ventral stream(V1-V2-V4-IT)存在明显的层级对应关系。
这项研究可能算是第一项比较CNN和大脑视觉脑区表征的研究,因此有重要的意义。目前有1500次左右的引用量。
2018年,James Dicarlo后续还有一项工作更细致对比了CNN和人类以及猴子的物体识别能力[2]。

这个任务不是分类任务,非常简单。就是看一张图片,然后给你两个选择,你要选出刚刚在图片中出现的物体。这张图片是由物体图片和不同背景合并生成的。
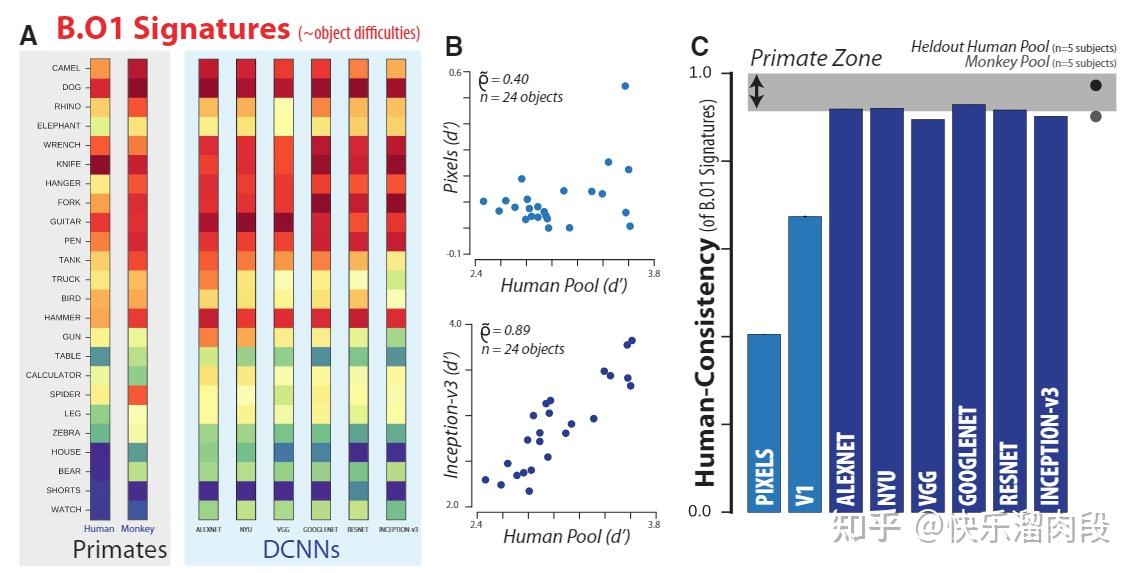
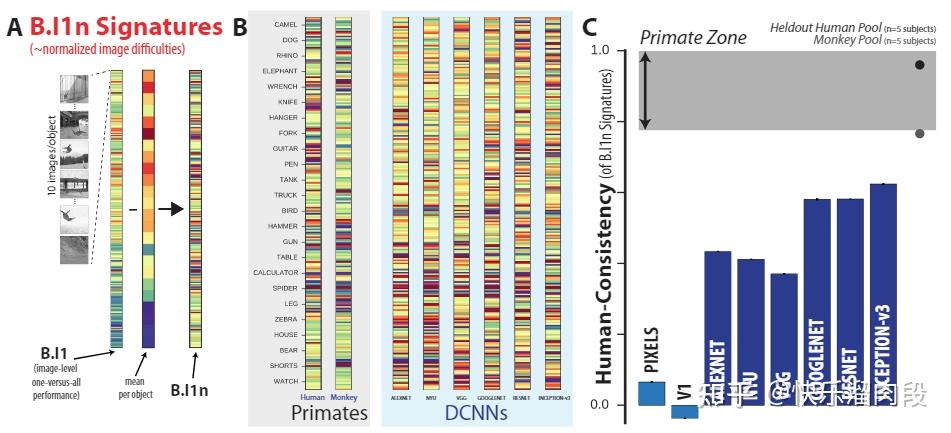
研究人员在Object-Level(某一物体所有图片的综合表现)以及Image-Level(每张图片会有很多repetition,单张图片上的表现)两个层级上对比了CNN和猴子人类的物体识别能力。
他们发现,在Object-Level上,CNN展现出与灵长类动物类似的物体识别能力(接近Primate Zone,即猴子/人的识别水平区域)。然而,如果考虑每一张图片表现的相似性(Image-Level),CNN和灵长类动物则有较大差异。
Image-Level上表现的差异说明,CNN和灵长类动物视觉系统对图片的处理机制上依然存在很大不同。
非监督学习模型
使用监督学习模型作为大脑视觉系统模型的一个问题在于,这和猴子人类的学习方式是不同的。人类在婴儿阶段不存在大量监督式学习,因此通常认为非监督学习是更自然的学习方式。
非监督学习的巨大优势在于模型可以从非标注数据中,通过构建监督信号,获得信息的表征。这在NLP领域是一项重要的方法,比如GPT-1在训练时,使用预测下文这一任务进行非监督预训练,学习文本的表征(训练数据为完整的文本材料,模型接受部分文本信息,预测下文,此时完整的文本材料就是groundtruth,因此不需要标注数据)。
2018年之后,计算机视觉领域比较重要的进展就是从NLP引入了生成式学习/对比学习等非监督的训练范式。代表性的工作像是kaiming的MAE[3],Hinton提出的对比学习模型simCLR[4]。
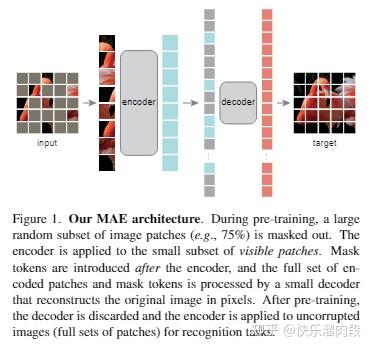
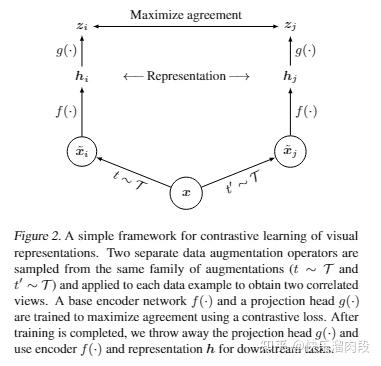
这些新提出的模型拥有的表征以及它们的学习方式是否和人类大脑有着更强的相似性是个非常有意思的问题。
Daniel Yamins(2014年PNAS文章的一作)在Hinton提出simCLR当年就发表一项非监督学习视觉模型表征的相关工作[5]。
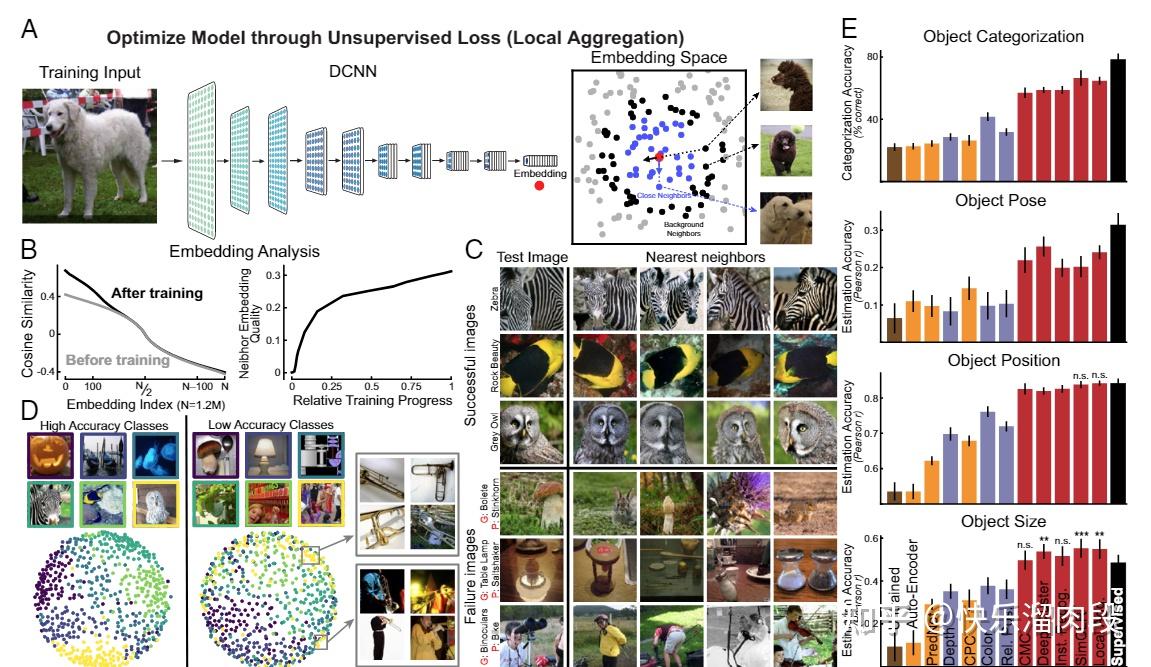
他们发现,非监督学习模型可以取得比监督学习模型更强的分类性能。并且,非监督学习模型可以取得很好的神经元活动预测效果 。
这项研究更有意思的一个部分是,他们使用SAYCam这一数据集训练了非监督模型。 这一数据集是从3个婴儿上收集到的第一人称视角的数据(就是把摄像头挂他们头上,从6个月到32个月,每周两小时)。所以这一数据集某种程度上代表着婴儿在人生的初始阶段所获得“训练”数据。
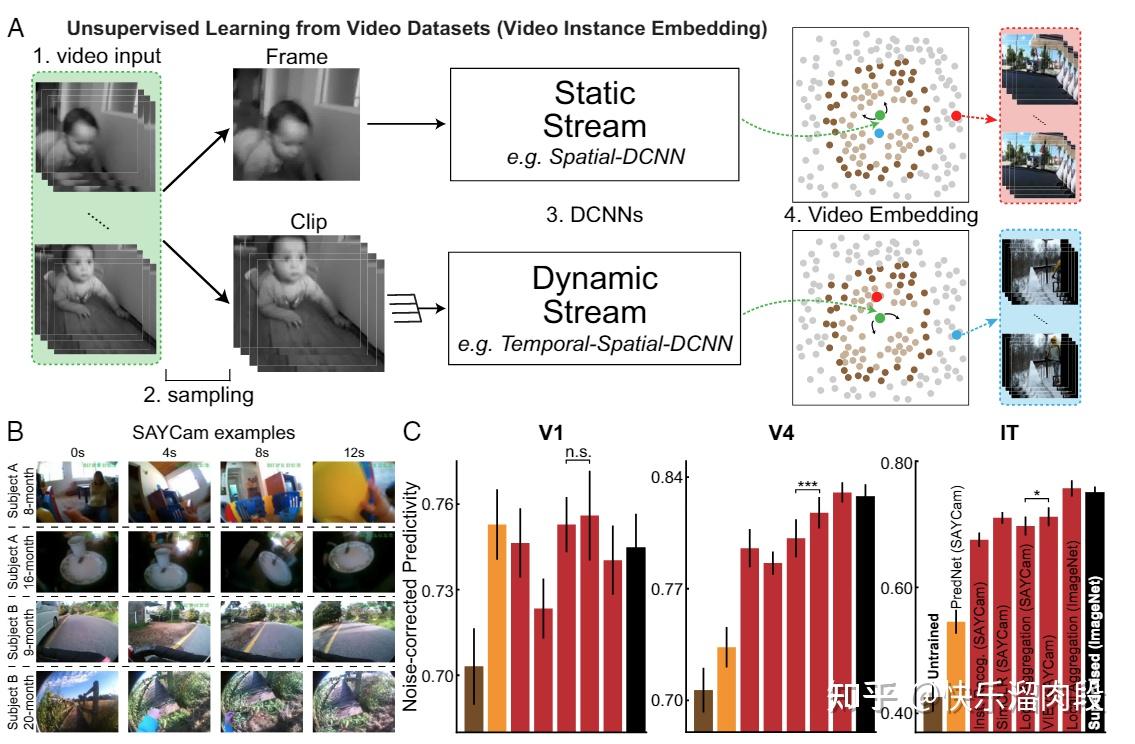
他们发现在SAYCam上进行非监督训练可以取得在ImageNet上进行监督训练类似类似的表征。
这既说明非监督训练范式的强大,也多少佐证了非监督学习是人类视觉学习主要方式这一结论。
Daniel Yamins是James Dicarlo的博后,他目前在stanford也建立了自己的实验室。他们很关注神经科学与AI的交叉方向(他们实验室就叫 NeuroAI lab),题主感兴趣也可以关注一波。
NeuroAILab - Home
解码大脑
目前人工智能的基础就是第二代神经网络模型。
神经网络模型的结构多少和大脑有一定的相似性,而且神经网络模型在各种任务上的优异表现也说明它具有非常强的拟合能力,因此可以作为大脑的解码器。
AI读心术
这一方向有非常多有趣的研究,而且这些研究多被媒体冠以“AI读心术”的名称。
比如,日本科学家使用stable diffsion通过解码人脑活动活动复现出人类真实看到的图片[6]。给人类看一张图片,记录人类大脑的fMRI数据,然后通过stable diffsion模型研究人员重新生成出了图片,而这些图片和人类看到的图片有着惊人的相似性。

得克萨斯大学奥斯汀分校的研究团队训练GPT解码出了人类大脑的语言信息[7]。这一结果的实现步骤是先收集模型训练数据:让人类被试心中默想文字内容,然后收集fMRI数据。
收集到的数据被用来训练GPT模型,然后就可以用该模型预测出这个人类被试脑中正在想象的文字信息。
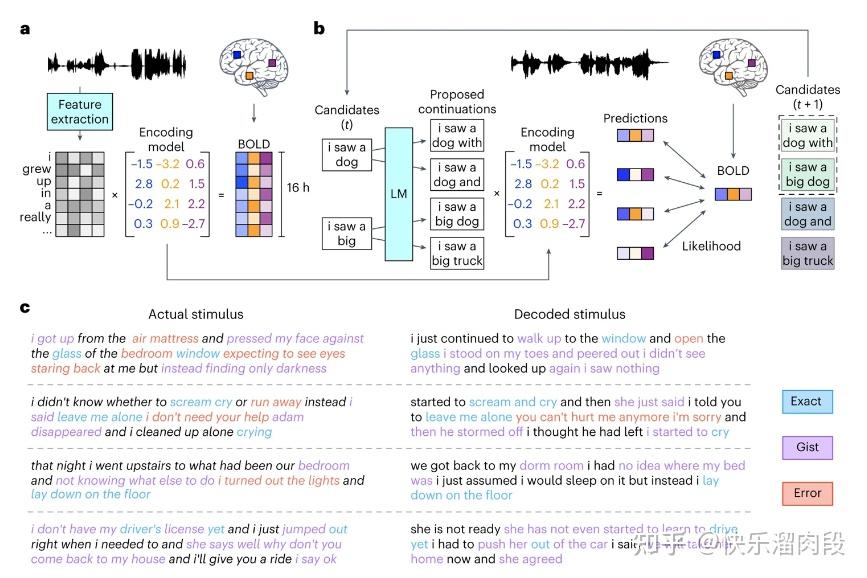
这项技术没有看上去那么唬人,因为通过这样方式训练出来的模型其实只适用于一个人,在另一个人身上表现就没有那么好了。
另一项登上Nature的研究应用对比学习模型[8],甚至可以根据小鼠大脑信息预测小鼠将要看到的视频片段。
AI读心重磅突破登Nature!大脑信号1秒被看穿,还能预测未来画面_腾讯新闻
具体来说,它们给小鼠不断重复的看一个视频片段,同时用该视频和小鼠大脑的神经元数据训练模型。模型因此获得了通过小鼠当前大脑活动预测出小鼠将要看到的下一帧图片的能力。所以严格来讲,这不算是从大脑活动重建出视频,而只是可以预测不同帧的顺序。
不过,这一项研究的重点也并不在于从大脑活动重建出视觉信息。研究人员的motivation在于利用对比学习模型开发出一种神经元数据的降维工具,通过将神经元数据降维,来获得神经元活动与动物行为更好的对应关系。
人工智能模型也被应用到脑机接口的技术中[9]。
简单来说,研究人员使用浅层的前馈神经网络代替了传统的kalman filter作为猴子手指运动速度的解码器。研究人员发现,相比于kalman滤波,神经网络解码器可以让解码设备获得36%的通量提升。
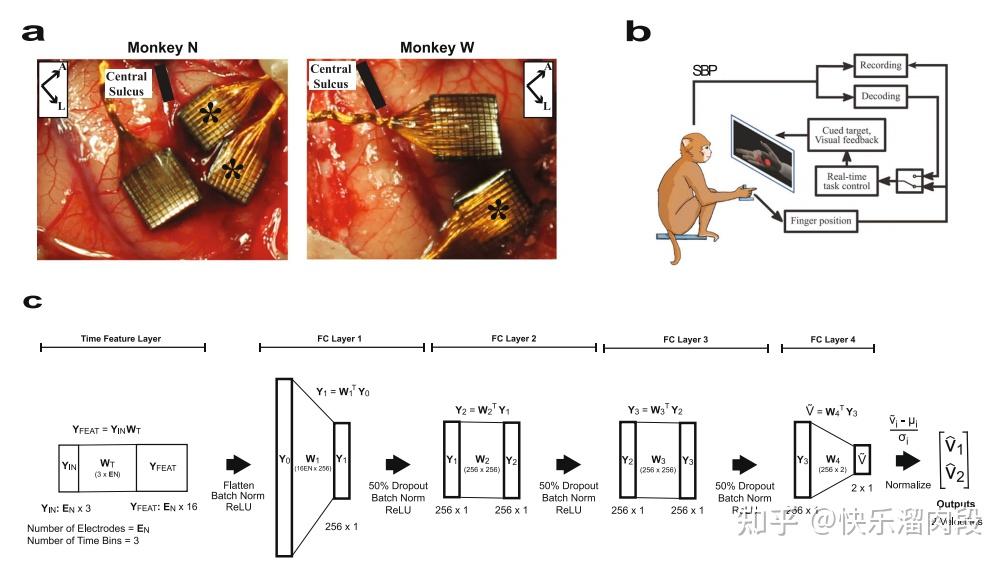
不过这样的浅层网络能不能被称为人工智能其实还是需要打一个问号的。