为什么很少拿神经网络来直接做滤波器呢?
On Measuring and Controlling the Spectral Bias of the Deep Image Prior (IJCV'2021)
度量与控制 Deep Image Prior 的谱偏移
这篇文章就是在解释为什么卷积、上采样可以当作滤波器来用
自监督去噪的文章收录在我的自监督去噪专栏,欢迎关注
自监督去噪论文专栏
自监督去噪大致可以分为三类模型

本文主要分享 On Measuring and Controlling the Spectral Bias of the Deep Image Prior (IJCV'2021)
度量与控制 Deep Image Prior 的谱偏移

作者来自
Subhransu Maji 同样也是 The Spectral Bias of the Deep Image Prior (NeurIPS Workshop'2019) 的作者

论文 ReadPaper 链接
https://readpaper.com/paper/3178474055https://readpaper.com/paper/29966694181. Introduction

这里解释一下DIP、逆问题、谱偏移三个概念
DIP 指的是 Deep Image Prior CVPR'2018 这篇文章,本文属于DIP系列论文
【自监督去噪系列一】Deep Image Prior (CVPR'2018)逆问题出现在 DIP 系列方法的综述 无训练的神经网络先验解决逆问题 TPAMI'2022,指的是给出观测结果 y 求出groundtruth 信号 x 的一类问题,详情请看:
【DIP 系列去噪方法综述】综述:使用无训练网络先验解决逆(反)成像问题的方法 (TPAMI'2022)谱偏移/频率原则是指神经网络拟合低频信息比高频信息快
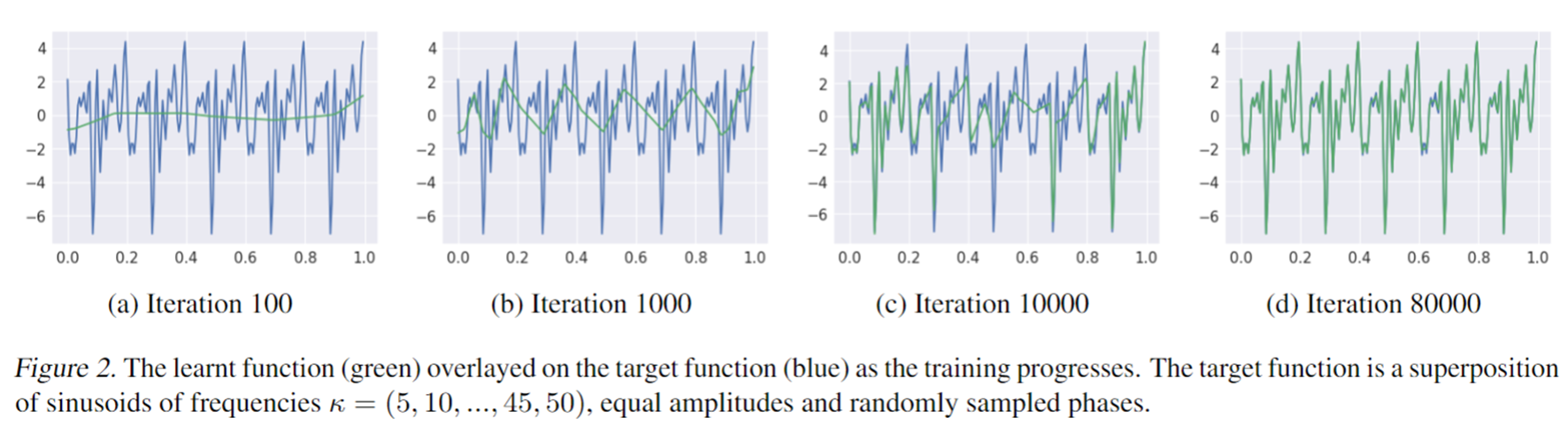
如图,绿色是神经网络的预测,蓝色是 Groundtruth,
随着网络不断迭代,绿色的线逐渐靠近蓝色的groundtruth
迭代过程中可以看到绿色线先学习到蓝色信号的低频部分,再学习蓝色信号的高频部分
谱偏移/频率原则出自两篇文章
一篇是2018图灵奖得主 Yoshua Bengio 的 On Spectral Bias of Deep Neural Networks (ICML'2018)
另一篇是上海交通大学 @许志钦 老师的 Frequency principle: Fourier analysis sheds light on deep neural networks. (Communications in Computational Physics'2020)
神经网络的简单偏好2. Method
2.1 频带一致性度量与网络退化

了解了傅里叶变换得到的频谱图之后,下面介绍一下频带一致性指标

看一下频带一致性 FBC 这一指标随着迭代次数增加会如何变化
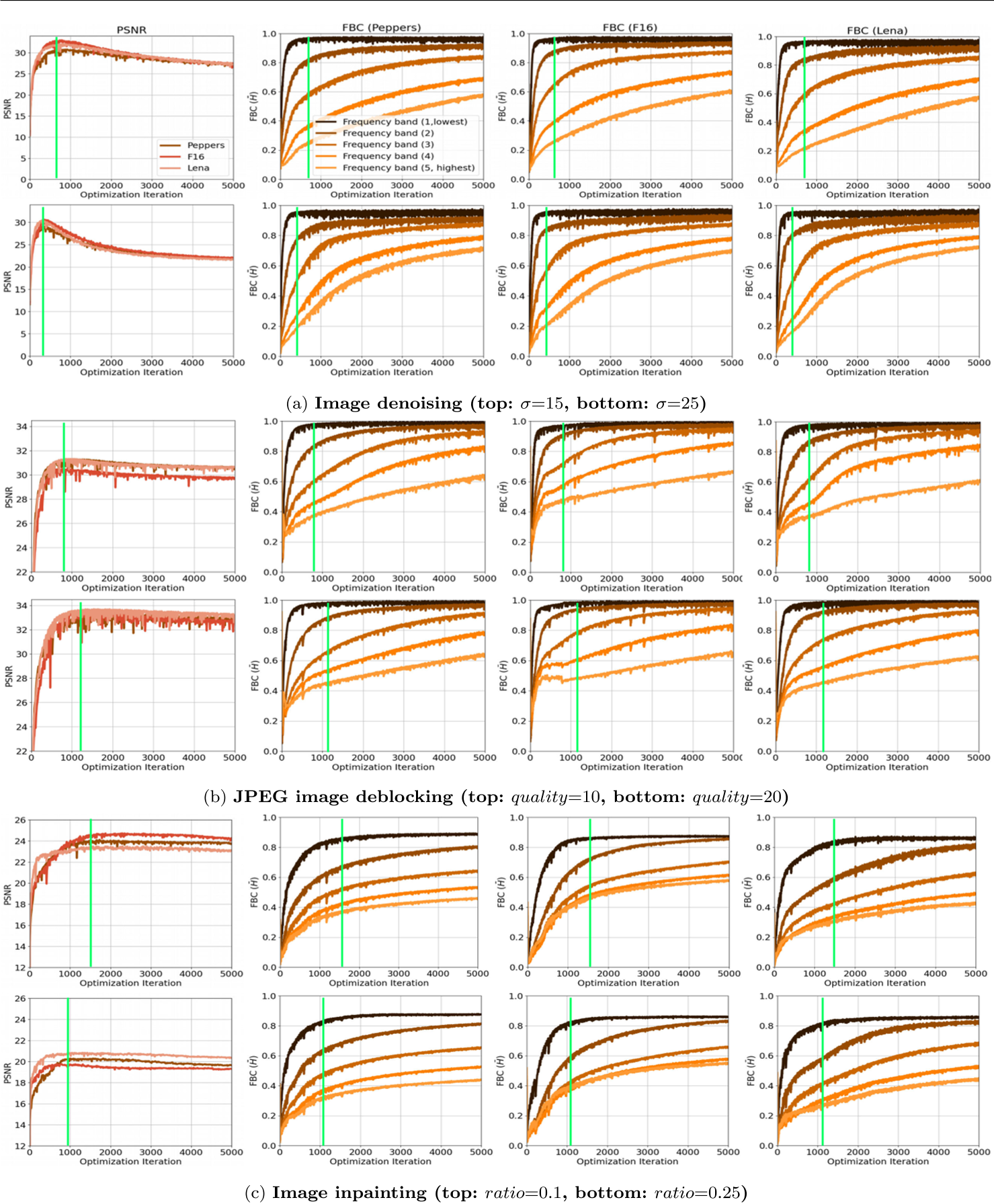
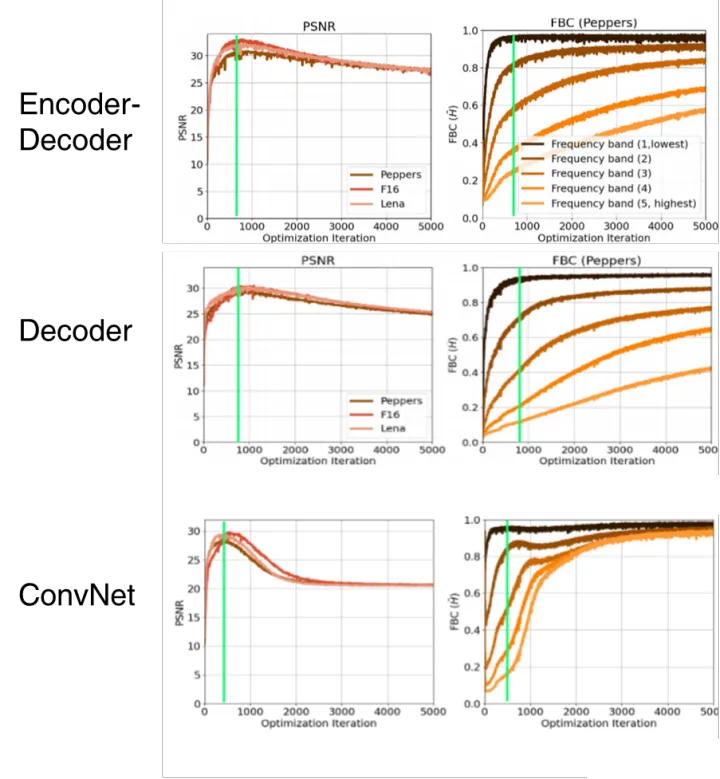
作者在三张图片 pepper、F16、Lena 上分别做实验
对三张图片 pepper、F16、Lena 加噪, 然后 DIP 去噪

第一列是预测图与目标图的 PSNR 随着迭代次数增加的变化图片
后面三列分别是三张图片 pepper、F16、Lena 的频带一致性随着迭代次数增加的变化图
可以得到以下几个观察:
- 随着 DIP 不断迭代,PSNR 会先达到最高再慢慢降低,即性能会达到峰值之后下降
- 验证了DIP有谱偏移现象:低频分量学得快且频带一致性高,高频分量学得慢且频带一致性低
- 在PSNR最高的时候(图中的绿色线),正好是 lowest 分量的频带一致性刚刚最高的时候
- 随着高频部分的频带一致性升高,PSNR开始下降
接下来,作者继续探索这种现象究竟与网络中的什么结构有关
作者分别使用 (a) 没有 Encoder 部分的 DIP; (b) 没有上采样层的 DIP ,做与之前相同去噪的实验
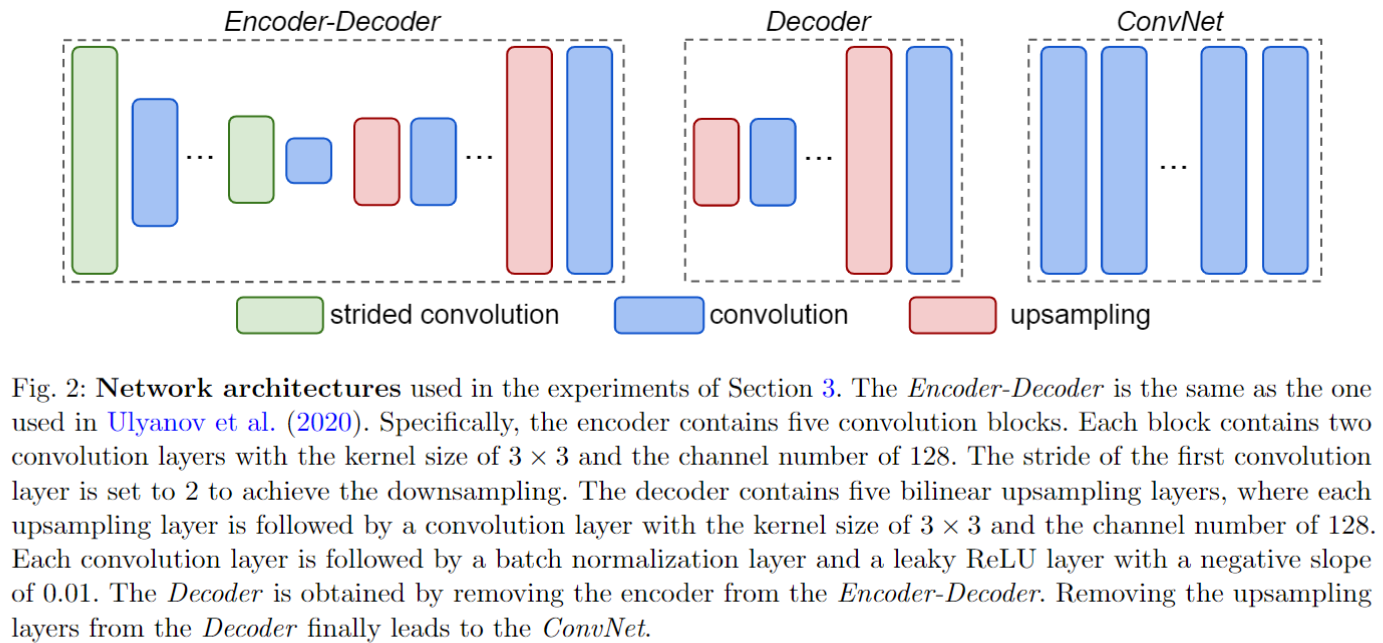
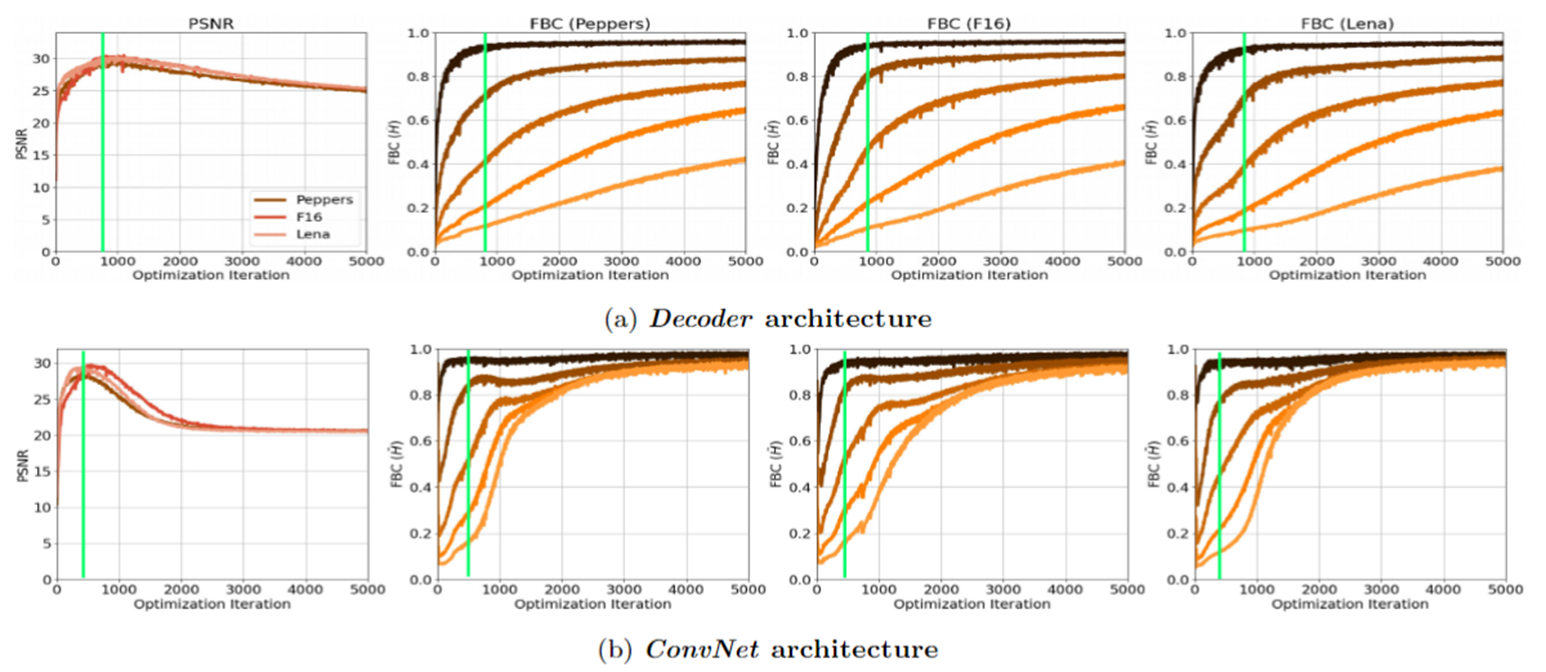
可以发现之前的几个结论还都适用,同时也有一些新发现:
- 谱偏移仍然存在
- Decoder 的效果和 DIP 差不多
- 无上采样层的 ConvNet 低频收敛比 Decoder 和 DIP 都快
- 无上采样层的 ConvNet 高频部分频带一致性比 Decoder 和 DIP 都高
- 无上采样层的 ConvNet 最大 PSNR 要比 Decoder 和 DIP 低
至此,可以得出结论
- 无训练网络先验方法 UNNP 可以解决逆图像问题的原因是学习低频比高频快,即谱偏移
- 高频分量分为结构高频分量与噪声高频分量,当网络开始学习噪声高频分量时,性能开始下降
- 上采样层提高PSNR,但是影响低频收敛速度,原因是引入低频bias
因此,为了防止网络退化,平衡性能与效率,网络优化方向:
- 由于没有性能差异,因此使用参数更少的 Decoder 结构替代 DIP 的 Encoder-Decoder
- 性能退化->抑制网络对高频噪声的学习
- 收敛加速->使用更好的上采样层
- 自动设置迭代次数,兼顾平衡性能与效率->停止策略
2.2 Lipschitz-controlled 卷积层
要了解如何控制网络学习高频内容,首先要从频域的角度来理解卷积
[CV] 通俗理解『卷积』——从傅里叶变换到滤波器
为了更好地分析如何控制卷积层,这里,需要引入 L-Lipschitz 连续的概念


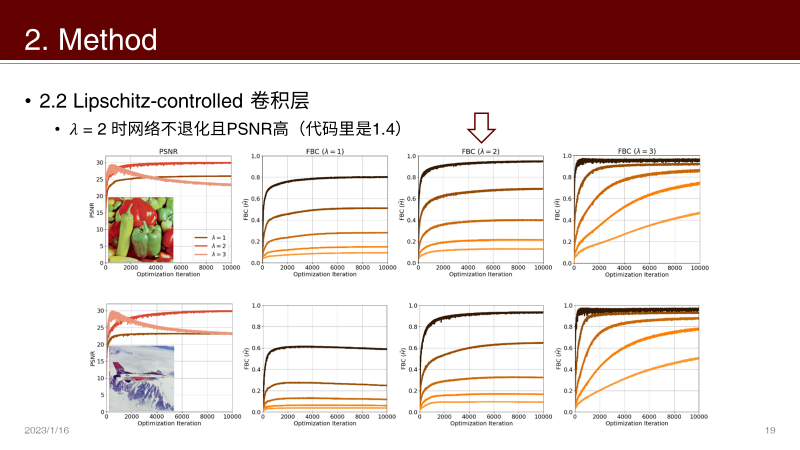
接下来的问题是 λ 选多少合适呢?
选1,PSNR太低,选3,网络由于学到了高频噪声产生了退化
那就取个中间值2吧,PSNR高并且网络不退化
卷积层分析完了,其他层会不会对卷积层参数有影响呢?

到这里,Lipschitz-controlled 卷积层部分就结束了
代码
核心
sigma = torch.max(torch.ones_like(sigma),sigma/self.ln_lambda)
setattr(self.module, self.name, w / sigma.expand_as(w))
class SpectralNorm(nn.Module):
def __init__(self, module, ln_lambda=2.0, name='weight'):
super(SpectralNorm, self).__init__()
self.module = module
self.name = name
self.ln_lambda = torch.tensor(ln_lambda)
if not self._made_params():
self._make_params()
def _update_u_v(self):
w = getattr(self.module, self.name + "_bar")
height = w.data.shape[0]
_,w_svd,_ = torch.svd(w.view(height,-1).data, some=False, compute_uv=False)
sigma = w_svd[0]
sigma = torch.max(torch.ones_like(sigma),sigma/self.ln_lambda)
setattr(self.module, self.name, w / sigma.expand_as(w))
def _made_params(self):
try:
w = getattr(self.module, self.name + "_bar")
return True
except AttributeError:
return False
def _make_params(self):
w = getattr(self.module, self.name)
w_bar = Parameter(w.data)
del self.module._parameters[self.name]
self.module.register_parameter(self.name + "_bar", w_bar)
def forward(self, *args):
self._update_u_v()
return self.module.forward(*args)
def conv(in_f, out_f, kernel_size=3, ln_lambda=2, stride=1, bias=True, pad='zero'):
downsampler = None
padder = None
to_pad = int((kernel_size - 1) / 2)
if pad == 'reflection':
padder = nn.ReflectionPad2d(to_pad)
to_pad = 0
convolver = nn.Conv2d(in_f, out_f, kernel_size, stride, padding=to_pad, bias=bias)
nn.init.kaiming_uniform_(convolver.weight, a=0, mode='fan_in')
if ln_lambda>0:
convolver = SpectralNorm(convolver, ln_lambda)
layers = filter(lambda x: x is not None, [padder, convolver, downsampler])
return nn.Sequential(*layers)
下面来看看上采样层怎么改进
2.3 Gaussian-Controlled 上采样层
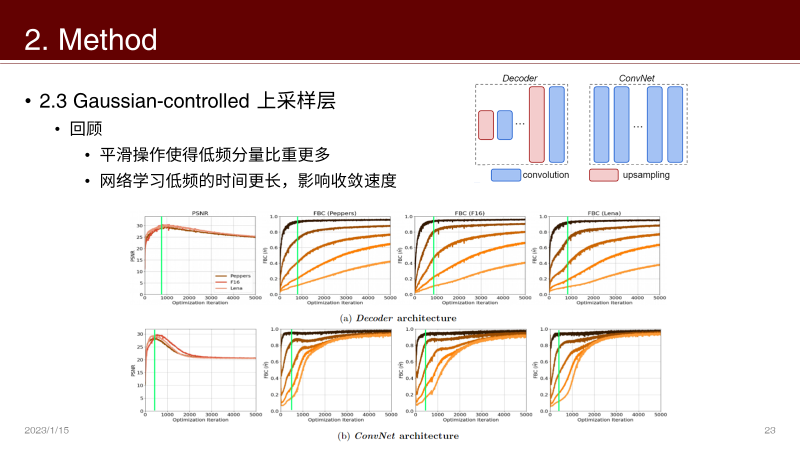
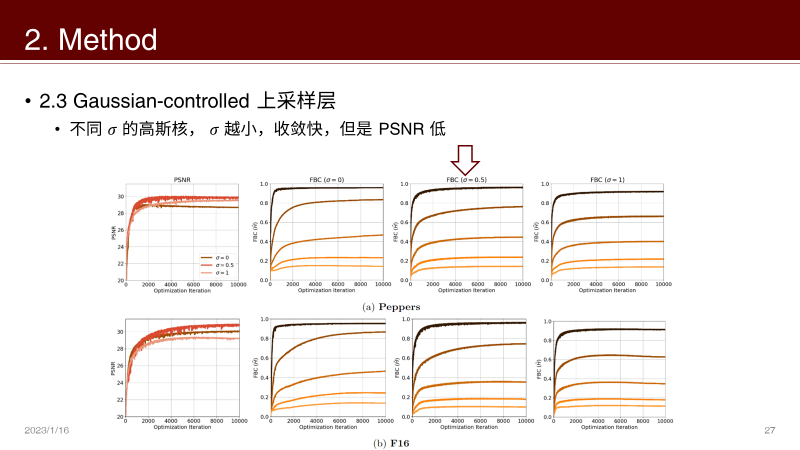
插值、最近邻上采样层的平滑操作会让网络收敛变慢,因此引入 Gaussian-controlled 上采样层
插值、最近邻上采样:变换到频域,发现其傅里叶系数随着频率增加而减小,相当于低通滤波器(来自 NeurIPS Workshop 2019 的论文)

之前分析过,上采样层的 over-smooth 导致其对高频有高阻抗性
低频分量的增多使得网络需要拟合低频内容更多,影响收敛速度
有没有能控制平滑程度的上采样方法呢?
转置卷积+高斯核了解一下
转置卷积:
抽丝剥茧,带你理解转置卷积(反卷积)_史丹利复合田的博客-CSDN博客_逆卷积和转置卷积转置卷积进行上采样的好处是什么?可以自定义核!这就是转置卷积的核心竞争力
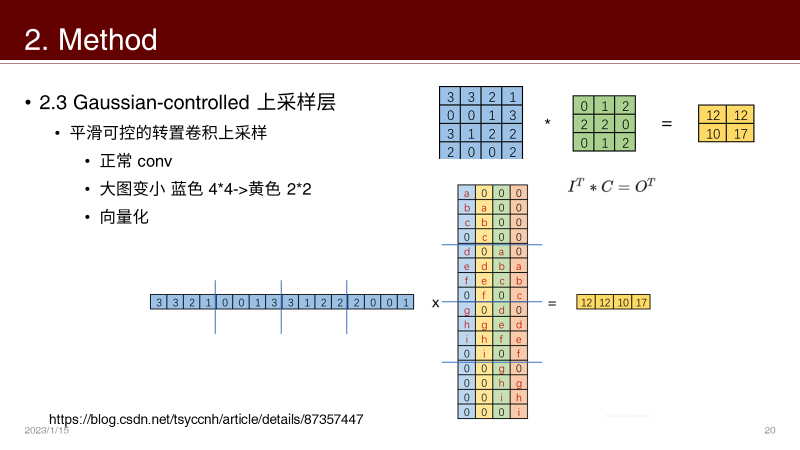
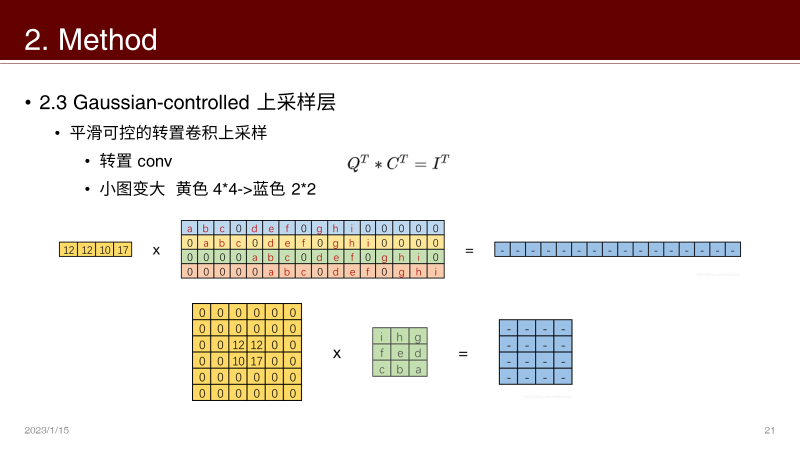
平滑程度可控,最容易想到的就是高斯核吧

实验:控制 σ 到合适的值,可以在不影响 PSNR 的前提下加速收敛
代码
核心就是nn.ConvTranspose2d 与高斯卷积核的参数 kernel
def get_kernel(kernel_width=5, sigma=0.5):
kernel = np.zeros([kernel_width, kernel_width])
center = (kernel_width + 1.)/2.
sigma_sq = sigma * sigma
for i in range(1, kernel.shape[0] + 1):
for j in range(1, kernel.shape[1] + 1):
di = (i - center)/2.
dj = (j - center)/2.
kernel[i - 1][j - 1] = np.exp(-(di * di + dj * dj)/(2 * sigma_sq))
kernel[i - 1][j - 1] = kernel[i - 1][j - 1]/(2. * np.pi * sigma_sq)
kernel /= kernel.sum()
return kernel
class gaussian(nn.Module):
def __init__(self, n_planes, kernel_width=5, sigma=0.5):
super(gaussian, self).__init__()
self.n_planes = n_planes
self.kernel = get_kernel(kernel_width=kernel_width,sigma=sigma)
convolver = nn.ConvTranspose2d(n_planes, n_planes, kernel_size=5, stride=2, padding=2, output_padding=1, groups=n_planes)
convolver.weight.data[:] = 0
convolver.bias.data[:] = 0
convolver.weight.requires_grad = False
convolver.bias.requires_grad = False
kernel_torch = torch.from_numpy(self.kernel)
for i in range(n_planes):
convolver.weight.data[i, 0] = kernel_torch
self.upsampler_ = convolver
def forward(self, x):
x = self.upsampler_(x)
return x
2.4 自动停止迭代
2.2 Lipschitz-controlled 卷积层解决了性能退化的问题
2.3 Gaussian-controlled 上采样层解决了收敛速度的问题
2.4 自动停止迭代解决不同任务需要手动设置不同迭代次数的问题
什么时候停止迭代?一定是收敛以后。所以要找一个确定收敛的指标

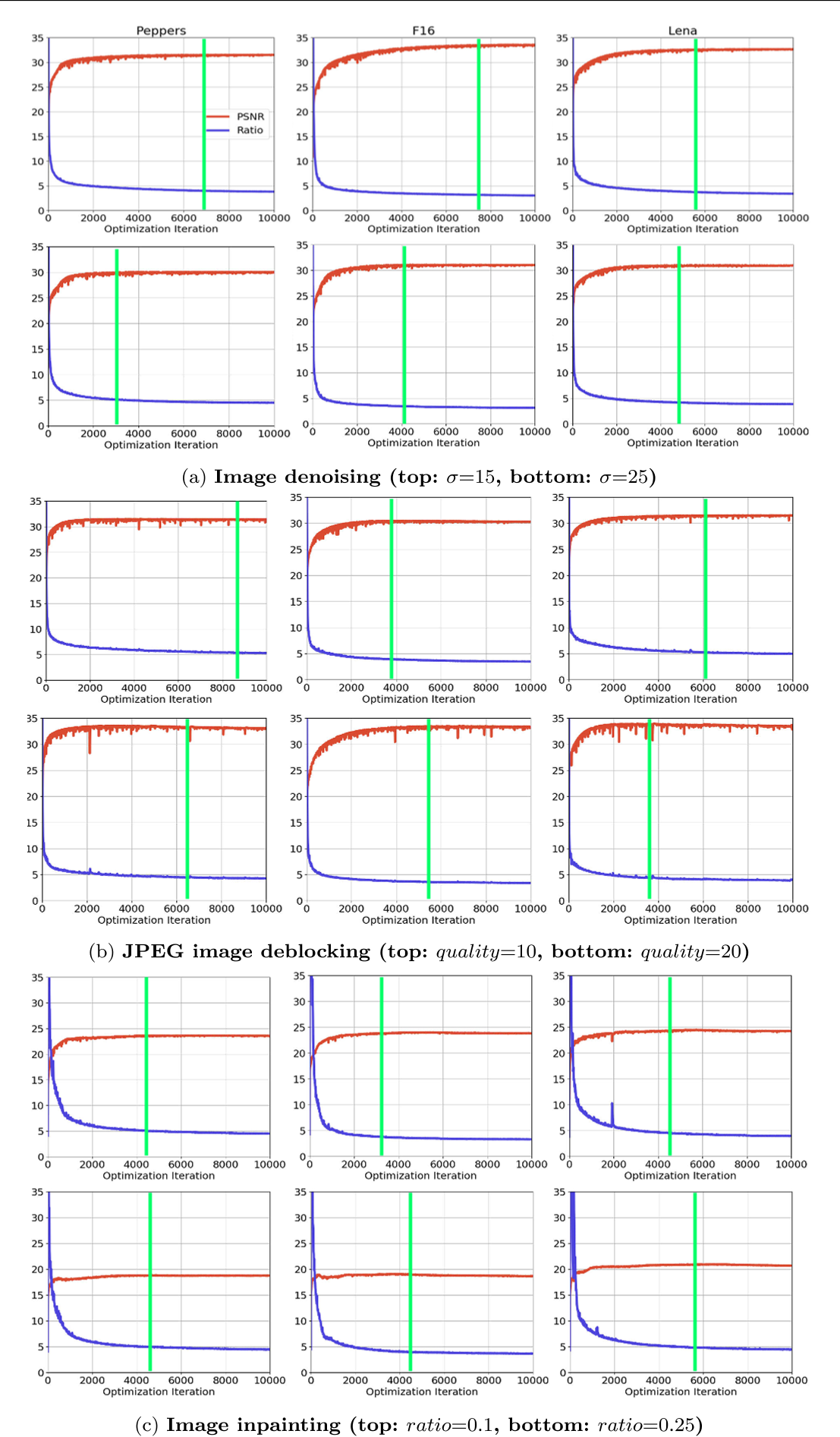
代码
#automatic stopping
blur_it = PerceptualBlurMetric (pre_img)#the blurriness of the output image
sharp_it = MLVSharpnessMeasure(pre_img)#the sharpness of the output image
ratio_it = blur_it/sharp_it#the ratio
if auto_stop:
ratio_list[i] = ratio_it
if i>ratio_iter*2:
ratio1 = np.mean(ratio_list[i-ratio_iter*2:i-ratio_iter])
ratio2 = np.mean(ratio_list[i-ratio_iter+1:i])
if np.abs(ratio1-ratio2)<ratio_epsilon:
print("The optimization is automatically stopped!")
out_np = torch_to_np(out)
save2img(out_np, "./figs/%s_denoised.png" % img_name)
exit()
3. Experiment
去噪结果对比
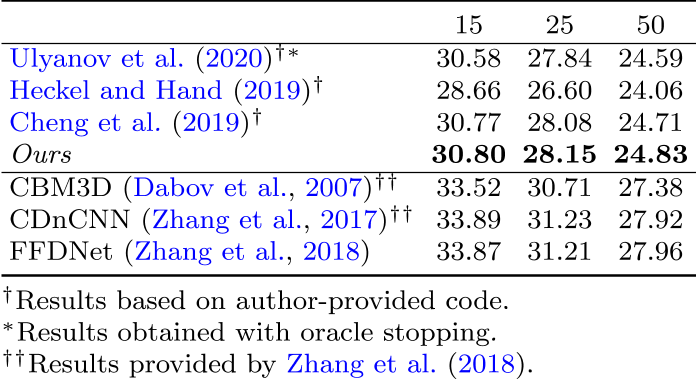
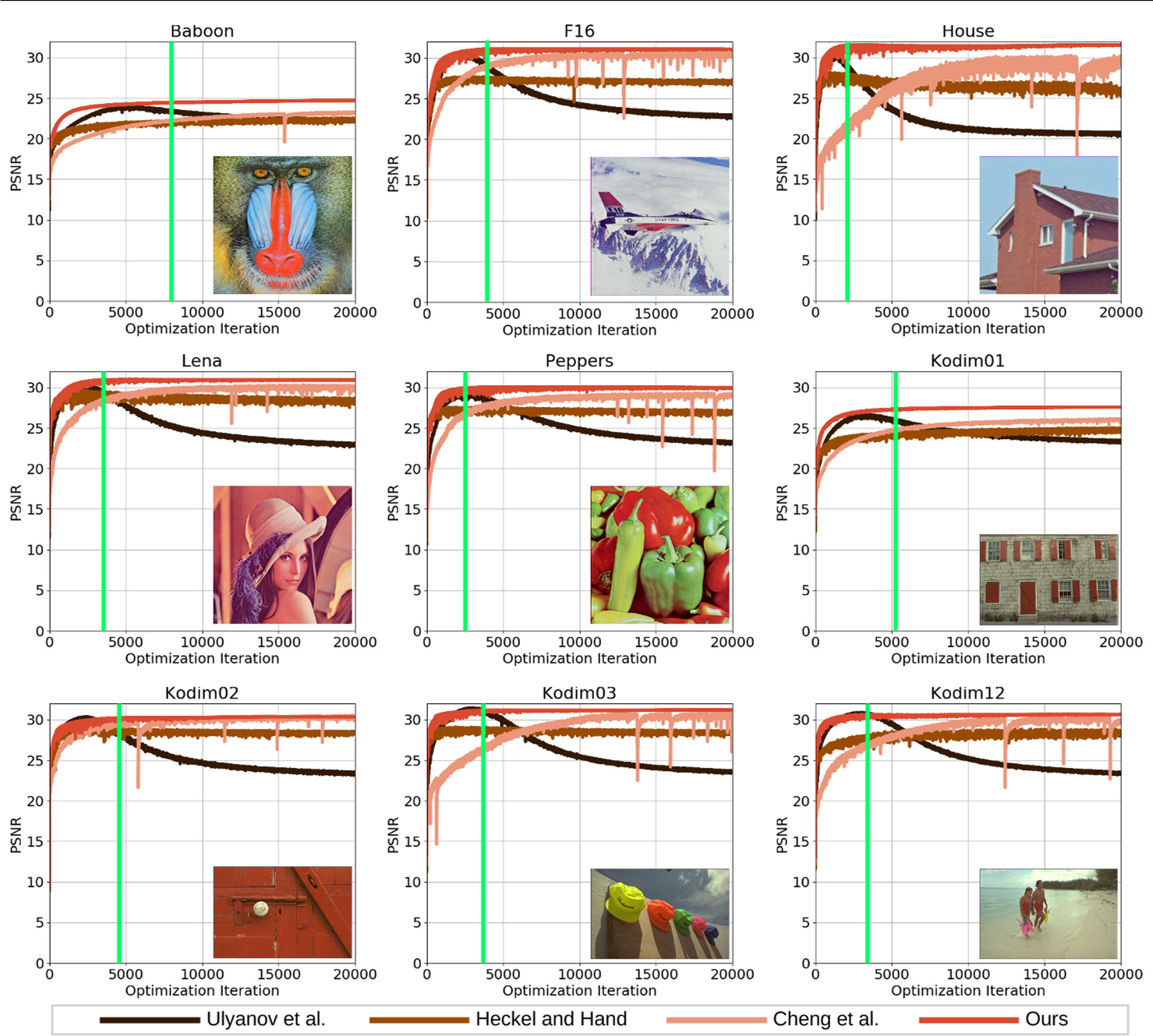
其他任务的自己看一下吧,都是这种图
4. Conclusion


终于肝完了
点赞关注收藏,顶会论文必中
