R 语言的特性如何帮助数据科学家更有效地进行数据分析和建模?
一文概述:
编程思想的重要性:
- 编程语法是散落在各处的知识碎片,编程思想将它们串在一起形成清晰脉络;
- 编程知识碎片,学的死知识,用的时候不知道选哪片,只能是瞎套用;
- 融入编程思想的编程语法,能够
- 引领你更快地、真正地理解和学会编程语法;
- 让你遇到问题知道从哪里开始思考,往哪个方向去思考;
我首创提出的tidyverse优雅数据编程思想:
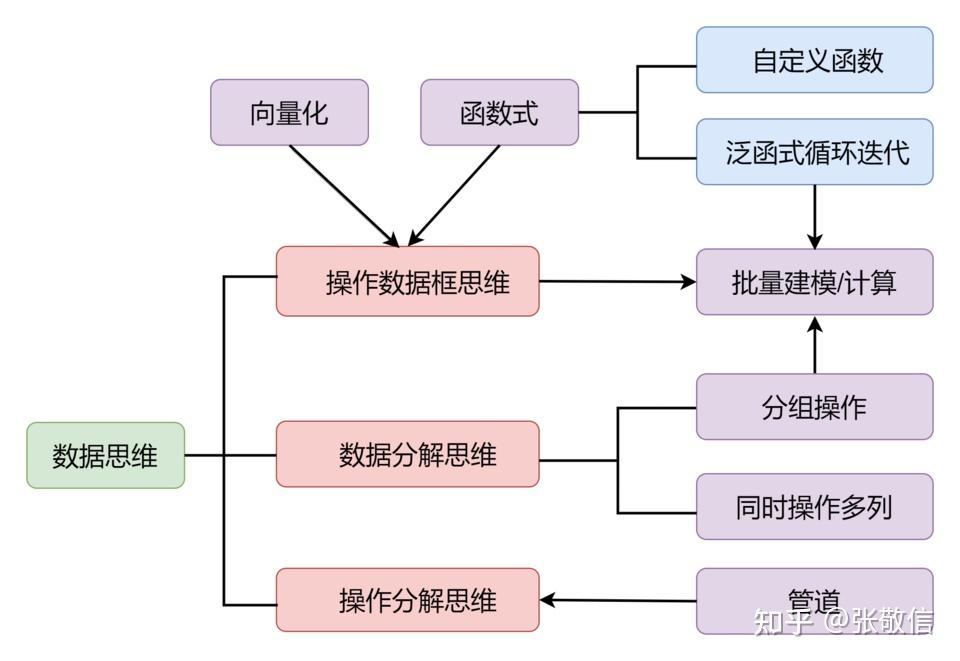
下面分别加以介绍,先设置数据文件根路径、加载包。
library(tidyverse)
library(rstatix)
1. 向量化
- 向量化,就是同时操作一个向量/矩阵的所有数据,对每个元素同时做相同操作
- 关键是要用整体考量的思维来思考、来表示运算
比如考虑 元一次线性方程组:
若从整体的角度来考量,引入矩阵和向量:
则可以向量化表示为:
例1 实现归一化算法
归一化,是将数值向量线性放缩到[0,1], 一般还同时考虑指标一致化,将正向指标(值越大越好)和负向指标(值越小越好)都变成正向。
正向指标:
负向指标:
借助简单实例 x=[4,1,5,8], 问题已足够简单不需分解。
- 若是正向指标,按第 1 个公式,按编程语法翻译成代码(要有意识地摒弃
for i in 1:4的逐元素迭代想法):
x = c(4, 1, 5, 8)
(x - min(x)) / (max(x) - min(x))
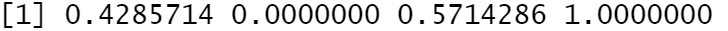
这里用到两种常用的向量化计算:
min(x): 函数作用在向量上(几乎所有自带R函数都是这么设计的)x - min(x): 向量减去标量(向量的每个元素都减去该标量)
另外,还有一种常用,比如:x * y(每个元素分别做乘法)
还有,若是负向指标,需要分支结构:
type = "+" # 标记正向指标
if(type == "+") {
(x - min(x)) / (max(x) - min(x))
} else {
(max(x) - x) / (max(x) - min(x))
}
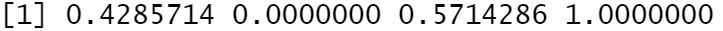
2. 自定义函数
- 要做一件事,拿一个简单实例,调试通过;再改写成一个函数,就可以一步到位、反复用、批量用、给别人用
- R中函数一般形式为:
函数名 = function(输入1, ..., 输入n) {
函数体
}
- 你只要把输入给它,它就能在内部进行相应处理,把你想要的返回值给你
- 定义函数就好比创造一个模具,调用函数就好比用模具批量生成产品
例2 将归一化封装为函数
rescale = function(x, type = "+") {
if(type == "+") {
(x - min(x)) / (max(x) - min(x))
} else {
(max(x) - x) / (max(x) - min(x))
}
}
# 测试
rescale(x) # 同rescale(x, "+")
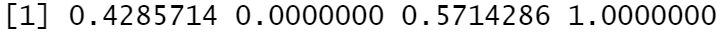
rescale(x, "-")
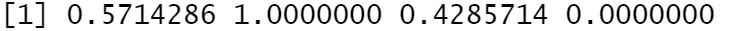
3. 泛函式循环迭代
循环迭代,就是依次对序列的每个元素,重复做同样的事情,并保存结果。
做一件事情,就是一个代码段,封装起来就是自定义一个函数
循环迭代,本质上就是将一个函数依次应用(映射)到序列的每一个元素上,表示出来即map(x, f)
两点说明:
- 序列:由一系列可以根据位置索引的元素构成,元素可以很复杂和不同类型;向量、列表、数据框都是序列
- 将
x作为第一个参数,是便于使用管道
purrr泛函式编程解决循环迭代问题的逻辑:
- 针对序列每个单独的元素,怎么处理它得到正确的结果,将之定义为函数,再
map到序列中的每一个元素,将得到的多个结果(每个元素作用后返回一个结果)打包到一起返回,并且可以根据想让结果返回什么类型选用 map 后缀。
循环迭代返回类型的控制:
map_chr, map_lgl, map_dbl, map_int: 返回相应类型向量map_dfr, map_dfc: 返回数据框列表,再按行、按列合并为一个数据框
函数参数.f是作用在序列.x的一个元素上,建议使用函数简写,例如:
表示为
\(x) x ^ 2 + 1
表示为
\(x, y) log(x + y^2) + 1
注: 这也是分解的思维,循环迭代要依次对序列中每个元素做某操作,只需要把对一个元素做的操作写清楚(即.f),剩下的交给map_*()就行了。
map_*(.x, .f, ...): 依次应用一元函数.f到一个序列.x的每个元素,...可设置.f的其它参数
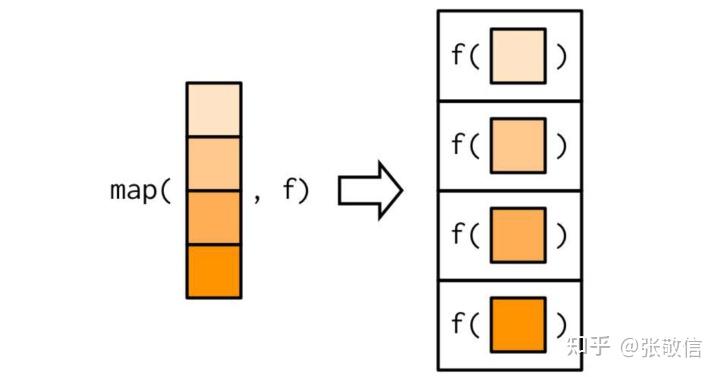
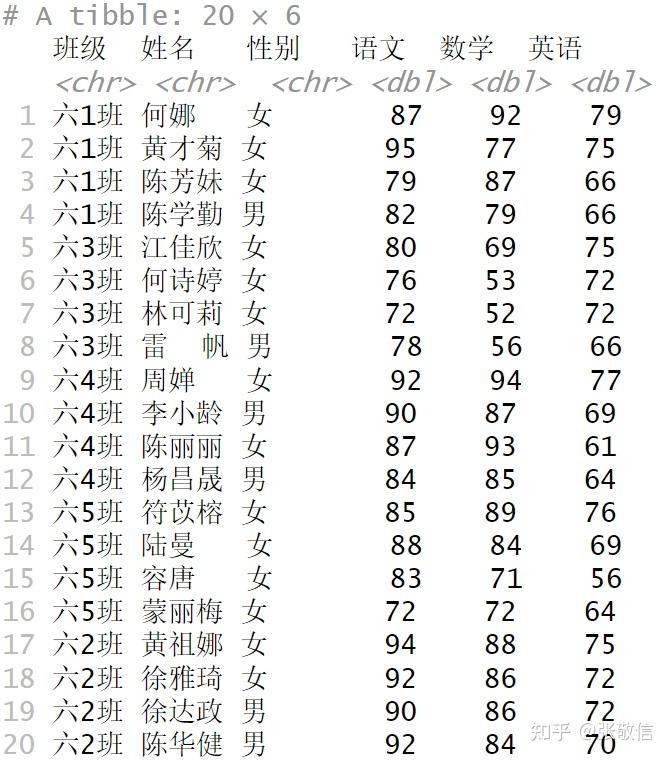
例3 在外面对数据框各列做归一化
- 数据框是序列,第1个元素是第1列
df[[1]], 第2个元素是第2列df[[2]], ......
map_dfc(iris[1:4], rescale) # 对4列分别做归一化
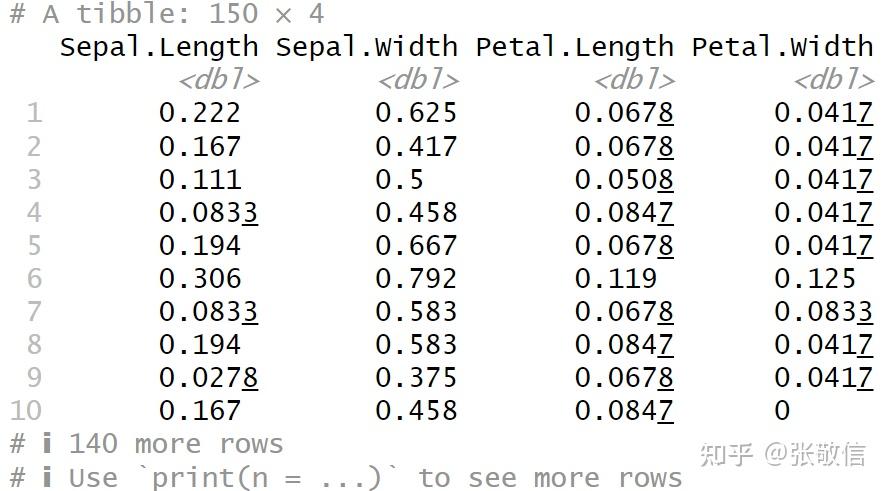
这是都当成正向指标,若+, -, -, +怎么办?
types = c("+", "-", "-", "+")
map2_dfc(iris[1:4], types, rescale)
例4 批量读取数据并按行合并
- 获取文件路径
- 循环迭代读取,同时合并结果
files = list.files("data/read_data", pattern = "csv",
full.names = TRUE, recursive = TRUE)
files

map_dfr(files, read_csv)
4. 管道
管道运算符%>%(magrittr包)或|>(R 4.1以来),通过管道将数据依次向前传递(从一个函数传给另一个函数),从而依次变换你的数据:
x %>% f() %>% g() # 同g(f(x))
表示依次对数据进行若干操作:先对数据x进行f操作, 接着对结果数据进行g操作
使用管道的好处:
- 避免使用过多的中间变量
- 程序可读性大大增强:对数据集依次进行一系列操作
数据默认传递给下一个函数的第一参数,否则需用.代替数据
5. 数据思维I: 操作数据框的思维
将向量化和函数式(自定义函数+泛函式循环迭代)编程思维,纳入到数据框中来:
- 向量化编程同时操作一个向量的数据,变成在数据框中操作一列的数据,或者同时操作数据框的多列,甚至分别操作数据框每个分组的多列;
- 函数式编程变成为想做的操作自定义函数(或现成函数),再依次应用到数据框的多个列上,以修改列或做汇总
记住:每次至少操作一列数据!
df = as_tibble(iris) %>%
set_names(str_c("x", 1:4), "Species")
例5 在数据框中做归一化
# df %>%
# mutate(x1 = rescale(x1), x2 = rescale(x2, "-"),
# x3 = rescale(x3, "-"), x4 = rescale(x4))
df %>%
mutate(across(1:4, rescale))
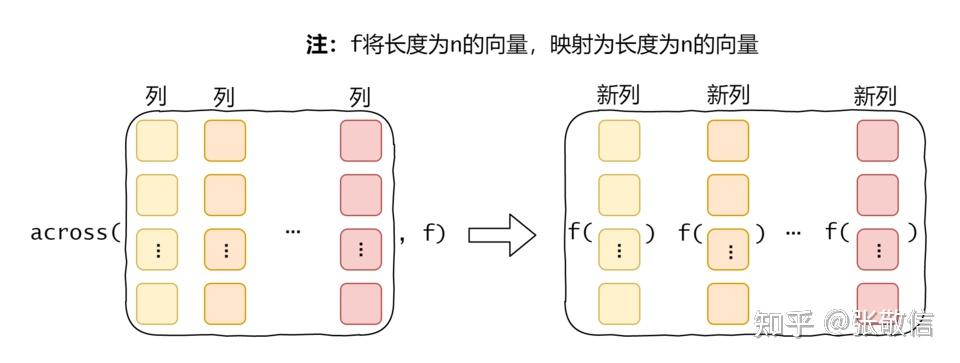
同时操作多列:across()同时操作多列,只需要选择要操作的列,对(每)一列上要做的操作,写成函数
6. 数据思维II: 操作分解的思维
复杂数据操作都可以分解为若干简单的基本数据操作:
- 数据连接
- 数据重塑(变成整洁数据:长宽转换、拆分/合并列等)
- 筛选行
- 排序行
- 选择列
- 修改列
- 分组汇总
一旦完成问题的梳理和分解,又熟悉每个基本数据操作,用“管道”流依次对数据做操作即可
例6 管道分解操作
load("data/SQL50data.rda")
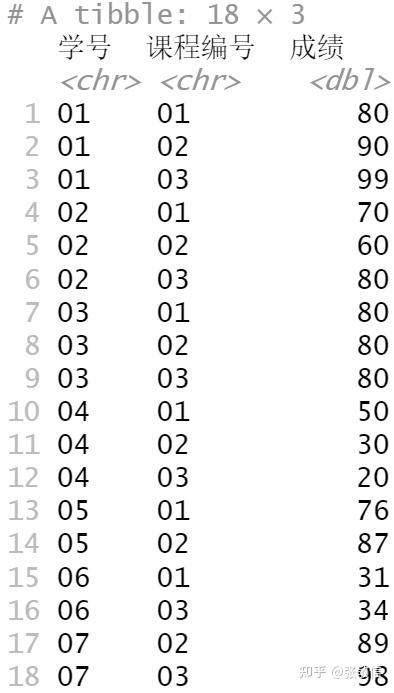
score
student
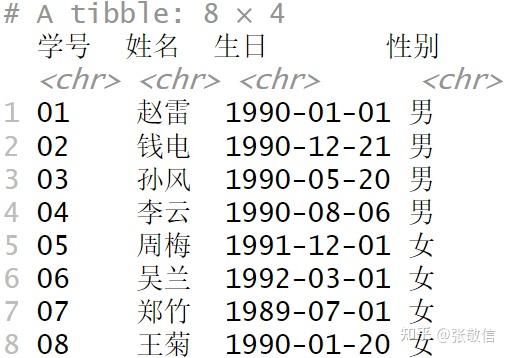
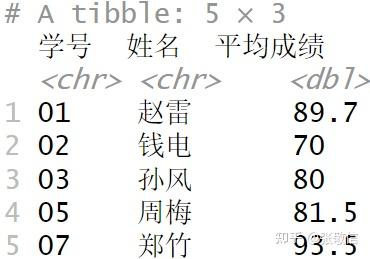
问题:查询平均成绩≥60分的学生学号、姓名和平均成绩。
分解问题:
- 先按学号分组汇总计算平均成绩
- 然后根据判断条件筛选行
- 再根据学号连接学生信息
- 最后选择想要的列
score %>%
summarise(平均成绩= mean(成绩), .by = 学号) %>%
filter(平均成绩 >= 60) %>%
left_join(student, by = "学号") %>%
select(学号, 姓名, 平均成绩)
7. 数据思维III: 数据分解的思维
分组操作:汇总/修改/筛选:想对数据框进行分组,分别对每组数据做操作,整体来想这是不容易想透的复杂事情,实际上只需做group_by()分组,然后把你要对一组数据做的操作实现
group_by + summarise: 分组汇总,结果是“有几个分组就有几个观测”group_by + mutate: 分组修改,结果是“原来几个观测还是几个观测”group_by + filter/slice: 分组筛选/切片,结果是“分别对每组取子集合一起”
例7 分组修改数据
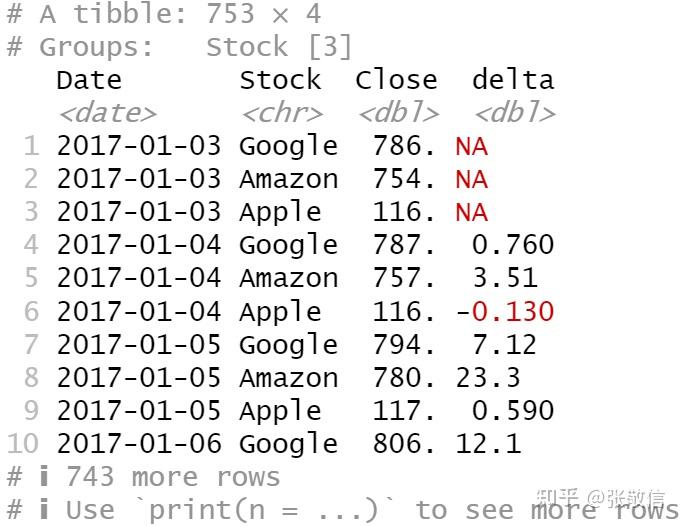
load("data/stocks.rda")
stocks

问题:分别计算每支股票的收盘价与前一天的差价。
- 分解的逻辑:只要对Stock分组,对一组数据(一支股票)怎么计算收盘价与前一天的差价,就怎么写代码
stocks %>%
group_by(Stock) %>%
mutate(delta = Close - lag(Close))
例8 分组t检验
ToothGrowth %>%
group_by(dose) %>%
t_test(len ~ supp)

8. 批量建模/计算
对数据做分组,批量地对每个分组建立同样模型/做同样计算,并提取和使用批量的模型/计算结果,这就是批量建模/计算。
“笨方法”手动分割数据、写for循环实现,再提取、合并结果也能实现。
数据思维做法更简洁优雅,仍是纳入到数据框中来做,用到嵌套数据框(列表列)+ mutate修改列 + map迭代。
你只需要解决:一个数据上的建模/计算。
例9 批量线性回归建模
- 分组嵌套,到嵌套数据框
df_nest = mtcars %>%
group_nest(cyl)
df_nest

- 查看每一个数据, 经常取出来调试用
dat = df_nest$data[[1]]
dat
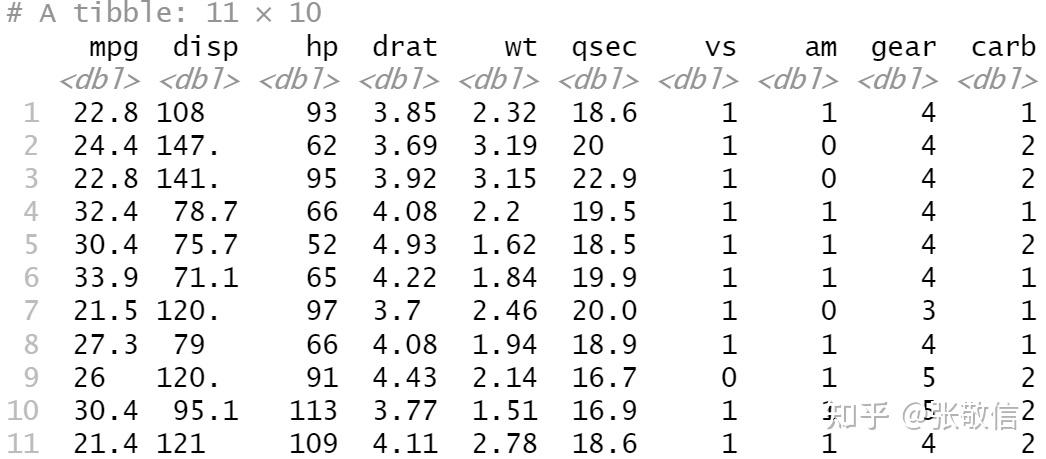
- 调试在一个数据上做的事情:
model = lm(mpg ~ disp, dat)
coef(model)
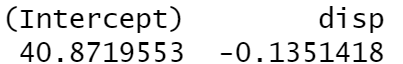
summary(model)$r.squared
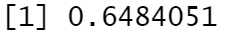
- 放到数据框里面去做:
rlt = df_nest %>%
mutate(model = map(data, \(x) lm(mpg ~ disp, x)),
coef = map(model, coef),
rsq = map_dbl(model, \(x) summary(x)$r.squared))
rlt

- 展开嵌套
rlt %>%
unnest_wider(coef)

总结一下贯穿始终的分解思维:
- 解决无从下手的复杂问题:分解为若干可上手的简单问题
- 循环迭代:分解为把解决一个元素的过程写成函数,再
map到一系列的元素 - 复杂的数据操作:分解为若干简单数据操作,再用管道连接
- 操作多组数据:分解为
group_by分组+操作明白一组数据 - 修改多列:分解为
across选择列+操作明白一列数据 - 批量建模/计算:分组嵌套数据或重抽样嵌套数据+调试明白对一个数据如何建模/计算
更多来自实际问题的tidyverse优雅数据编程案例
关于base R与tidyverse
我的观点:
- 没有必要先学习
base R, 强烈建议直接从tidyverse入门R语言编程,没有base R基础效果更佳!我的R书很少涉及base R, 照样涵盖所有基本编程语法,不影响解决各种各样的R编程问题。 - 将
base R当作是一个R包来看待,其中的某些好用函数,完全可以使用。 - 没有必要搞
base R与tidyverse对立,Python用户从来都是热烈拥抱numpy, pandas, matplotlib, sklearn, 更易学、易用干嘛要排斥。 - 近年来,国内不思进取、墨守成规的坚守
base R, 已经严重阻碍了国内R语言的发展,越来越小众化、边缘化,我希望更多的人特别是高校教师,能够加入使用和推广以tidyverse为代表的R新技术的行列!
附免费学习资源:
我的R新书完整课件,免费可在线运行版(和鲸网):
- 第一部分 - R基础语法与tidyverse优雅数据编程
- 第二部分 - R应用统计与探索性数据分析