 "分块"搜索结果 1 条
"分块"搜索结果 1 条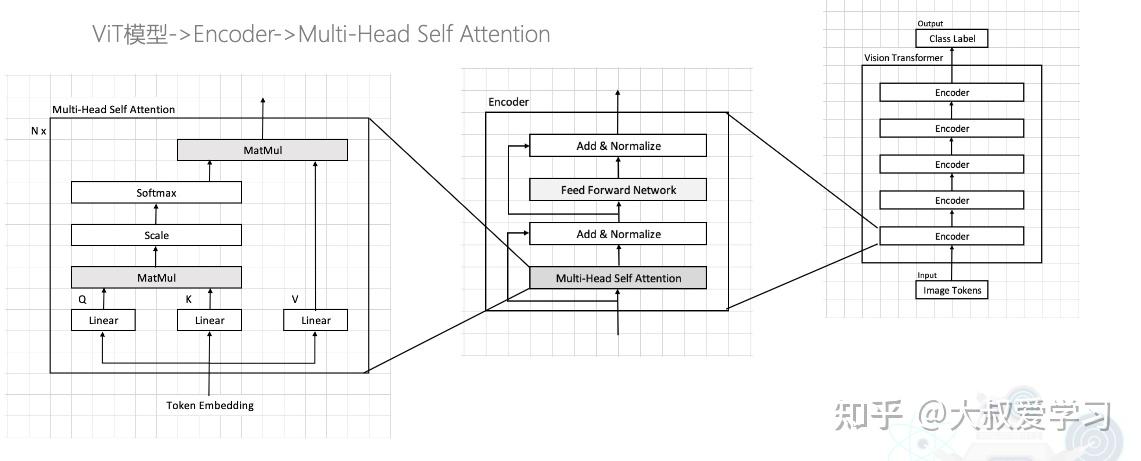
为什么vision transformer的self-attention要分块计算attention?
Patch Embedding 回顾 Seq2Seq中的attention在Transformer之前的RNN,其实已经用到了注意力机制。Seq2Seq。 对于Original RNN,每个RNN的输入,都是对应一个输出。对于original RNN,他的输入和输出必须是一样的。 在处理不是一对一的问题时,提出了RNN Seq2Seq。也就是在前面先输入整体,然后再依次把对应的输出出来。 虽然Seq2Seq解决了输入和输出不定是相同长度的问题,但是我们所有信息都存在模型的一定地方,我们叫上下文,…